Saturn Cloud Pro
(See other plans)AI/ML Infrastructure Hosted on Saturn Cloud Hardware
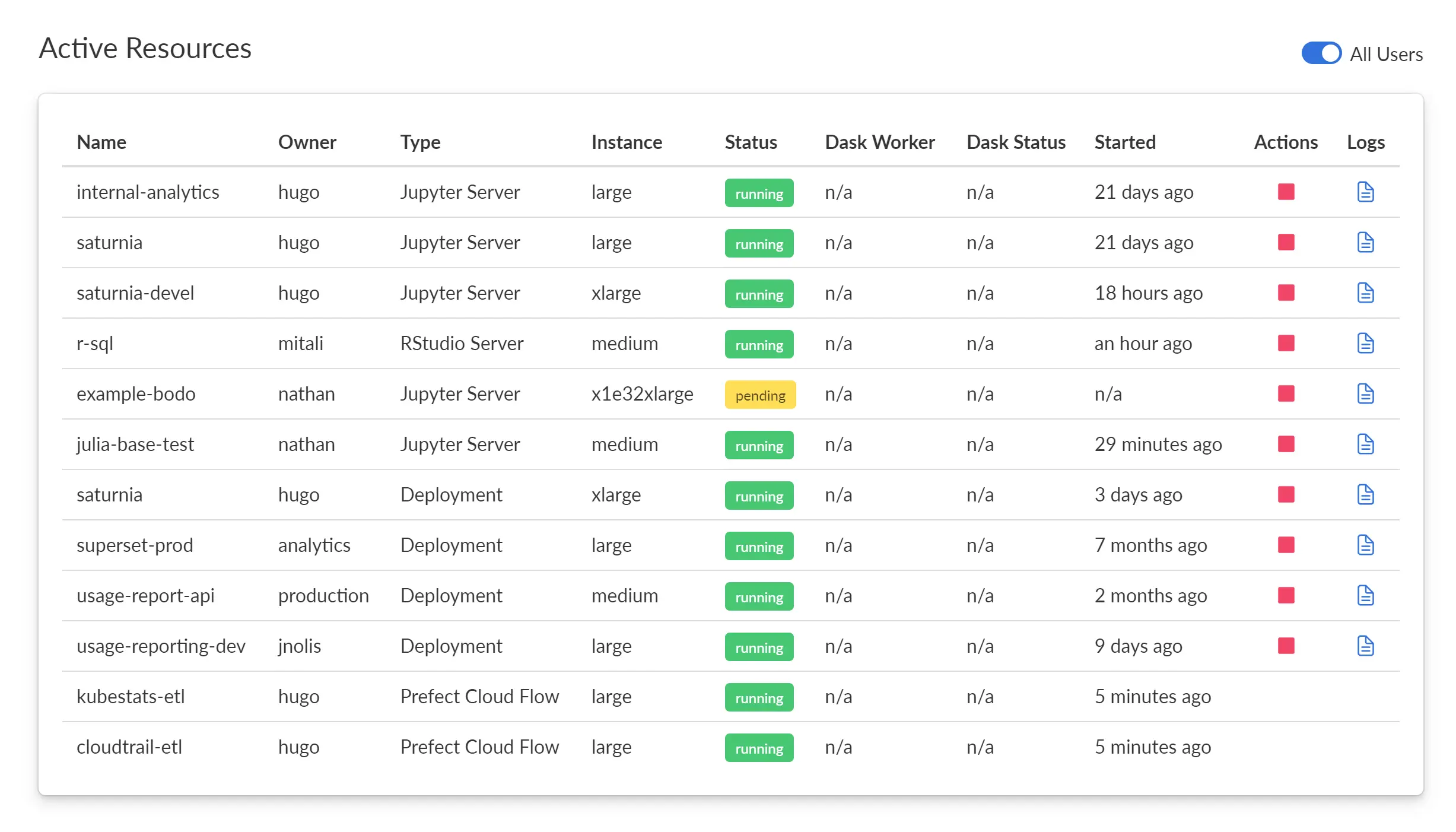
Saturn Cloud Pro let you work as a team on the cloud without having to set up any backend infrastructure. Your team will have immediate access to hardware hosted by Saturn Cloud, and your work will be isolated from other hosted users.
Organization admins can add or remove users, manage resource access, create groups, and more. Prices are based on how much your team has used resources. All organization usage will be charged to a single credit card.
NVIDIA H100
1xH100
$2.95/Hr
$1.99/hr
200 GB Memory
16 vCPUs
1 vGPU
Great for training and fine-tuning medium to large AI models with a balance of power and cost.
NVIDIA H100
8xH100
$23.6/Hr
1600 GB Memory
128 vCPUs
8 vGPU
Best for large-scale model training and distributed compute workloads like LLMs, diffusion models, etc.
NVIDIA H200
1xH200
$2.95/Hr
200 GB Memory
16 vCPUs
1 vGPU
Slight performance uplift over H100; great for high-throughput inference or efficient fine-tuning.
NVIDIA H200
8xH200
$23.6/Hr
1600 GB Memory
128 vCPUs
8 vGPU
Solid choice for enterprise-grade setup for generative models and intensive compute pipelines.
NVIDIA 4XLarge
4XLarge
$1.59/Hr
256 GB Memory
64 vCPUs
0 vGPU
NVIDIA 2XLarge
2XLarge
$0.4/Hr
64 GB Memory
16 vCPUs
0 vGPU
NVIDIA Large
Large
$0.09/Hr
16 GB Memory
4 vCPUs
0 vGPU
AWS T3
t3.medium
$0.15/Hr
4 GB Memory
2 vCPUs
0 vGPU
AWS R5
r5.large
$0.195/Hr
16 GB Memory
2 vCPUs
0 vGPU
AWS R5
r5.xlarge
$0.375/Hr
32 GB Memory
8 vCPUs
0 vGPU
AWS R5
r5.2xlarge
$0.75/Hr
64 GB Memory
8 vCPUs
0 vGPU
AWS R5
r5.4xlarge
$1.515/Hr
128 GB Memory
16 vCPUs
0 vGPU
AWS R5
r5.8xlarge
$3.03/Hr
256 GB Memory
32 vCPUs
0 vGPU
AWS R5
r5.12xlarge
$4.53/Hr
384 GB Memory
48 vCPUs
0 vGPU
AWS R5
r5.16xlarge
$6.045/Hr
512 GB Memory
64 vCPUs
0 vGPU
AWS X1
x1.16xlarge
$10.005/Hr
976 GB Memory
64 vCPUs
0 vGPU
AWS X1
x1.32xlarge
$20.01/Hr
1952 GB Memory
128 vCPUs
0 vGPU
AWS X1e
x1e.16xlarge
$20.01/Hr
1952 GB Memory
64 vCPUs
0 vGPU
AWS X1e
x1e.32xlarge
$40.035/Hr
3904 GB Memory
128 vCPUs
0 vGPU
AWS T4
g4dn.xlarge
$0.15/Hr
16 GB Memory
4 vCPUs
1 vGPU
Entry-level GPU; ideal for testing, small inference jobs, or development environments.
AWS T4
g4dn.4xlarge
$0.57/Hr
64 GB Memory
16 vCPUs
1 vGPU
Affordable choice for batch inference or lightweight training with moderate memory needs.
AWS T4
g4dn.8xlarge
$1.155/Hr
128 GB Memory
32 vCPUs
1 vGPU
Solid middle-ground for model tuning and image generation with modest GPU memory needs.
AWS T4
g4dn.metal
$3.45/Hr
384 GB Memory
96 vCPUs
8 vGPU
Fully unlocked instance for high-parallelism workloads; great for multi-container pipelines.
AWS V100
p3.2xlarge
$1.095/Hr
61 GB Memory
8 vCPUs
1 vGPU
Suitable for classic deep learning models, moderate batch size training, or experimentation.
AWS V100
p3.8xlarge
$4.395/Hr
244 GB Memory
32 vCPUs
4 vGPU
Powerful setup for training medium-to-large models and running intensive parallel tasks.
AWS V100
p3.16xlarge
$8.79/Hr
488 GB Memory
64 vCPUs
8 vGPU
Top-tier legacy compute; best for larger models, multi-GPU training, or fast inference at scale.
AWS A10G
g5.xlarge
$1.5/Hr
16 GB Memory
4 vCPUs
1 vGPU
Single A10G (24GB); great for small finetunes, LoRA tests, and quick protos.
AWS A10G
g5.2xlarge
$1.815/Hr
32 GB Memory
8 vCPUs
1 vGPU
1×A10G with more CPU/RAM; smoother data prep + medium-size inference.
AWS A10G
g5.4xlarge
$2.43/Hr
64 GB Memory
16 vCPUs
1 vGPU
1×A10G, ample RAM; stable larger-batch inference and preprocessing.
AWS A10G
g5.8xlarge
$3.675/Hr
128 GB Memory
32 vCPUs
1 vGPU
High-RAM single GPU for memory-heavy finetunes, embeddings, video/image pipelines.
AWS A10G
g5.12xlarge
$8.505/Hr
192 GB Memory
48 vCPUs
4 vGPU
4×A10G; multi-GPU training, distributed inference, parallel batch generation.
AWS A10G
g5.16xlarge
$6.135/Hr
256 GB Memory
64 vCPUs
1 vGPU
Maxed single-GPU node; big-RAM ETL + training where 1 GPU is enough.
AWS A10G
g5.24xlarge
$12.21/Hr
384 GB Memory
96 vCPUs
4 vGPU
4×A10G with huge RAM; bigger-context finetunes and heavy data pipelines.
AWS A10G
g5.48xlarge
$24.42/Hr
768 GB Memory
192 vCPUs
8 vGPU
8×A10G in one box; data-parallel training or very high-throughput inference.
AWS C5
c5.xlarge
$0.255/Hr
8 GB Memory
4 vCPUs
0 vGPU
AWS C5
c5.2xlarge
$0.51/Hr
16 GB Memory
8 vCPUs
0 vGPU
AWS C5
c5.4xlarge
$0.915/Hr
32 GB Memory
16 vCPUs
0 vGPU
AWS C5
c5.9xlarge
$2.295/Hr
72 GB Memory
36 vCPUs
0 vGPU
AWS C5
c5.12xlarge
$3.06/Hr
96 GB Memory
48 vCPUs
0 vGPU
AWS C5
c5.18xlarge
$4.59/Hr
144 GB Memory
72 vCPUs
0 vGPU
AWS C5
c5.24xlarge
$6.12/Hr
192 GB Memory
96 vCPUs
0 vGPU
AWS C5
c5.metal
$6.12/Hr
192 GB Memory
96 vCPUs
0 vGPU
| Cloud | Type | Availability | Memory (GB) | vCPUs | vGPUs | Price/ Hour | |
|---|---|---|---|---|---|---|---|
| 1xH100 | On-demand | 200 | 16 | 1 | $2.95/Hr 1.99/hr (With 3 months term) | ||
| 8xH100 | On-demand | 1600 | 128 | 8 | $23.6/Hr | ||
| 1xH200 | On-demand | 200 | 16 | 1 | $2.95/Hr | ||
| 8xH200 | On-demand | 1600 | 128 | 8 | $23.6/Hr | ||
| 4XLarge | On-demand | 256 | 64 | 0 | $1.59/Hr | ||
| 2XLarge | On-demand | 64 | 16 | 0 | $0.4/Hr | ||
| Large | On-demand | 16 | 4 | 0 | $0.09/Hr | ||
| t3.medium | On-demand | 4 | 2 | 0 | $0.15/Hr | ||
| r5.large | On-demand | 16 | 2 | 0 | $0.195/Hr | ||
| r5.xlarge | On-demand | 32 | 8 | 0 | $0.375/Hr | ||
| r5.2xlarge | On-demand | 64 | 8 | 0 | $0.75/Hr | ||
| r5.4xlarge | On-demand | 128 | 16 | 0 | $1.515/Hr | ||
| r5.8xlarge | On-demand | 256 | 32 | 0 | $3.03/Hr | ||
| r5.12xlarge | On-demand | 384 | 48 | 0 | $4.53/Hr | ||
| r5.16xlarge | On-demand | 512 | 64 | 0 | $6.045/Hr | ||
| x1.16xlarge | On-demand | 976 | 64 | 0 | $10.005/Hr | ||
| x1.32xlarge | On-demand | 1952 | 128 | 0 | $20.01/Hr | ||
| x1e.16xlarge | On-demand | 1952 | 64 | 0 | $20.01/Hr | ||
| x1e.32xlarge | On-demand | 3904 | 128 | 0 | $40.035/Hr | ||
| g4dn.xlarge | On-demand | 16 | 4 | 1 | $0.15/Hr | ||
| g4dn.4xlarge | On-demand | 64 | 16 | 1 | $0.57/Hr | ||
| g4dn.8xlarge | On-demand | 128 | 32 | 1 | $1.155/Hr | ||
| g4dn.metal | On-demand | 384 | 96 | 8 | $3.45/Hr | ||
| p3.2xlarge | On-demand | 61 | 8 | 1 | $1.095/Hr | ||
| p3.8xlarge | On-demand | 244 | 32 | 4 | $4.395/Hr | ||
| p3.16xlarge | On-demand | 488 | 64 | 8 | $8.79/Hr | ||
| g5.xlarge | On-demand | 16 | 4 | 1 | $1.5/Hr | ||
| g5.2xlarge | On-demand | 32 | 8 | 1 | $1.815/Hr | ||
| g5.4xlarge | On-demand | 64 | 16 | 1 | $2.43/Hr | ||
| g5.8xlarge | On-demand | 128 | 32 | 1 | $3.675/Hr | ||
| g5.12xlarge | On-demand | 192 | 48 | 4 | $8.505/Hr | ||
| g5.16xlarge | On-demand | 256 | 64 | 1 | $6.135/Hr | ||
| g5.24xlarge | On-demand | 384 | 96 | 4 | $12.21/Hr | ||
| g5.48xlarge | On-demand | 768 | 192 | 8 | $24.42/Hr | ||
| c5.xlarge | On-demand | 8 | 4 | 0 | $0.255/Hr | ||
| c5.2xlarge | On-demand | 16 | 8 | 0 | $0.51/Hr | ||
| c5.4xlarge | On-demand | 32 | 16 | 0 | $0.915/Hr | ||
| c5.9xlarge | On-demand | 72 | 36 | 0 | $2.295/Hr | ||
| c5.12xlarge | On-demand | 96 | 48 | 0 | $3.06/Hr | ||
| c5.18xlarge | On-demand | 144 | 72 | 0 | $4.59/Hr | ||
| c5.24xlarge | On-demand | 192 | 96 | 0 | $6.12/Hr | ||
| c5.metal | On-demand | 192 | 96 | 0 | $6.12/Hr | ||
| Storage | price per GB/ month | ||||||
| $0.20 | |||||||
