Will Large Language Models (LLMs) Transform the Future of Language?
Introduction
It’s not often that a chatbot makes headlines, but Chat-GPT is no ordinary chatbot. With its ability to generate coherent and contextually appropriate responses, it quickly becomes a favorite of users worldwide (and a nightmare for the stockholders of Cheggs and teachers). Chat GPT is spearheaded by the private research company Open AI.
The artificial intelligence lab in San Francisco was founded in 2015 as a non-profit organisation attempting to create “artificial general intelligence,” or AGI, which is essentially software that is as intelligent as humans. Since Nov 2022, the number of visitors to Chat GPT’s website has skyrocketed (see Figure 1).
Figure 1: Monthly Visits To the 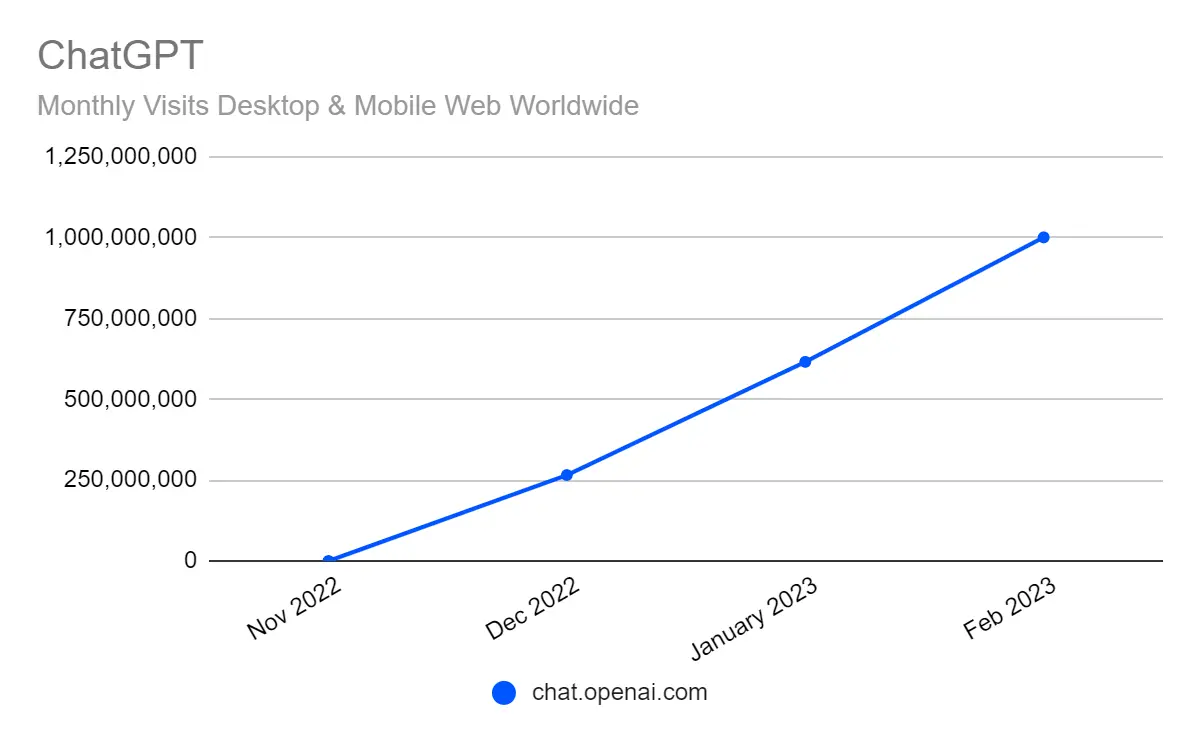
Figure 1: Monthly Visits To the ChatGPT Website
(https://www.similarweb.com/blog/insights/ai-news/chatgpt-1-billion/)In February 2023, ChatGPT topped 1 billion visits from 153 million unique visitors. Chat-GPT is more than just a virtual assistant - it’s a game-changer in the world of Large Language Models (LLMs). With its advanced language capabilities and ability to generate almost human-like responses, it’s clear that we’re entering a new era of AI-driven communication. Of course, Chat-GPT’s stunning debut begs to question what LLMs are and what sets them apart from natural language processing (NLP) models.
Large Language Models(LLMS): Origins and Evolution
LLMs are artificial intelligence (AI) models that analyse and comprehend natural language. These models are constructed utilising neural networks, which are algorithms based on the structure and function of the human brain. LLMs are trained on vast amounts of text data, which enables them to learn language patterns and relationships. This training data typically includes diverse textual sources, including novels, articles, and social media posts. LLMs are designed to enable machines to generate coherent and contextually appropriate language, enabling them to perform various tasks, including language translation, question responding, text generation, and more. While Chat GPTs are the latest bright stars of the AI galaxy, Language Models trace their origins to the 1950s. Following is a chronology of language models:
Early Language Models: In the 1950s and 1960s, researchers began developing early language models that could perform simple language processing tasks. These models were based on rule-based systems and did not have the sophisticated machine-learning algorithms we have today.
Neural Language Models: In the late 2000s and early 2010s, neural language models began to gain popularity. These models used neural networks to process language, enabling them to learn from large amounts of data and improve over time. One of the early examples of a neural language model was the recurrent neural network (RNN), which was used for tasks such as speech recognition and machine translation.
The Emergence of Transformers: In 2017, researchers at Google introduced the Transformer architecture, a type of neural network that uses self-attention mechanisms to process language. Transformers were a significant breakthrough in natural language processing (NLP) and have been used to develop some of the most advanced LLMs to date.
GPT-1: OpenAI released the GPT-1 model, a deep learning model capable of natural language processing, in 2016. GPT-1 has been pre-trained on a large corpus of text and 117 million parameters, allowing it to produce high-quality, context-appropriate language. It has a vocabulary of more than 40,000 subwords, allowing it to comprehend and produce complex language. However, GPT-1 is a unidirectional model, which means it can only use information from the past to generate language, limiting its ability to generate contextually appropriate responses in certain situations. It cannot comprehend long-range dependencies and contextual relationships between words, resulting in less precise language generation.
GPT-2: In 2018, OpenAI released the GPT-2 model, an upgraded GPT-1 with improved language understanding and generation capabilities. OpenAI also developed the GPT-2 fine-tuning method, which allows the model to be fine-tuned to specific tasks and industries. GPT-2 is a significantly larger model than GPT-1, with 1.5 billion parameters as opposed to GPT-1’s 117 million. This larger model size enables GPT-2 to learn more intricate language patterns and relationships, generating more accurate language. GPT-2 was trained using a novel, more efficient method that involved unsupervised pre-training followed by supervised fine-tuning. This method improved GPT-2’s ability to learn from the vast corpus of text data it was trained on. GPT-2 can generate highly realistic and coherent language, generating numerous paragraphs of text that are contextually appropriate and difficult to distinguish from the human-written text. In addition, GPT-2 made fewer grammatical errors and can perform a broader range of NLP tasks than GPT-1, including translation, question answering, and summarisation.
GPT-3: In 2020, OpenAI released the GPT-3 (Generative Pre-trained Transformer 3) model, one of the most advanced LLMs currently available. GPT-3 has been trained on enormous data and can generate highly realistic and coherent language responses. the most advanced version of GPT yet, it has 175 billion parameters. GPT-3 can perform specific NLP tasks without prior training or fine-tuning, a capability known as zero-shot learning. This means that GPT-3 can generalise from its training data and perform tasks it has never seen before. Owing to its unprecedented model size, GPT-3 can generate highly coherent and contextually appropriate language that is difficult to distinguish from the human-written text. It can generate entire articles, stories, and even grammatically correct and semantically meaningful poetry. GPT-3 can perform a broader range of NLP tasks than GPT-1 and GPT-2, including language translation, question answering, and text completion. It can also perform arithmetic, database querying, and code generation tasks. OpenAI has also released the DALL-E2, a follow-up to DALL-E. This model generates images from natural language descriptions 2021: OpenAI introduces its new language model, Ada, designed to be more efficient, accurate, and less biased than previous models.
Since GPT-3, researchers and developers have made advancements in LLMs. This includes developing more efficient training algorithms, experimenting with different architectures, and exploring new applications for LLMs, such as medicine and law. In 2022, OpenAI released GPT-4, a model that surpasses GPT-3 in terms of performance and capabilities.
Large Language Models (LLMs) and Natural Language Processing (NLP)
Natural Language Processing (NLP) and Large Language Models (LLMs) are closely related but distinct concepts. NLP is an artificial intelligence (AI) subfield concerned with the interaction between computers and human language. NLP is the application of computational methods to analyse, comprehend, and generate human language. NLP techniques are employed in numerous applications, including machine translation, sentiment analysis, speech recognition, and text classification. On the other hand, LLMs are a machine learning model specifically intended to process and comprehend natural language. LLMs are constructed using neural network architectures and trained on massive quantities of text data, which enables them to generate coherent and context-appropriate language.
LLMs are a subset of NLP, but they are not identical. Beyond LLMs, NLP incorporates a much broader range of techniques and applications. In addition to neural networks, NLP can include rule-based systems, statistical models, and machine-learning techniques.
NLP is an AI field that incorporates many techniques and applications related to human language. LLMs are a specific machine learning model developed to process and comprehend natural language.

The Transformative Power of Transformers
Transformers are a robust neural network architecture that has revolutionised the field of NLP. They allow us to process text data in a way that captures the complex relationships between words, which is critical for many NLP tasks. Transformers are designed to process data sequences, such as sentences or paragraphs, and are known for capturing long-term dependencies and relationships between words. They differ from traditional neural networks in using self-attention mechanisms, lack of recurrence, and greater parallelizability. These characteristics make them particularly well-suited to processing natural language and have been instrumental in developing advanced LLMs like GPT-3. The self-attention mechanism enables the model to evaluate the significance of each word in a sequence as it processes it.
A Transformer model comprises an encoder and a decoder at a high level. Encoder accepts an input sequence, such as a sentence or paragraph, and generates a sequence of concealed representations, one for each word in the input sequence. The decoder then produces an output sequence from these hidden representations, such as a translated sentence or an answer to a query. The self-attention mechanism is an integral part of the Transformer’s architecture. It enables the model to prioritise various parts of the input sequence when processing each word based on the relative importance of each word to the current task. This is accomplished by computing attention scores between each pair of words in the input sequence and using these scores to weigh each word’s contribution to the output (see Figure 2).
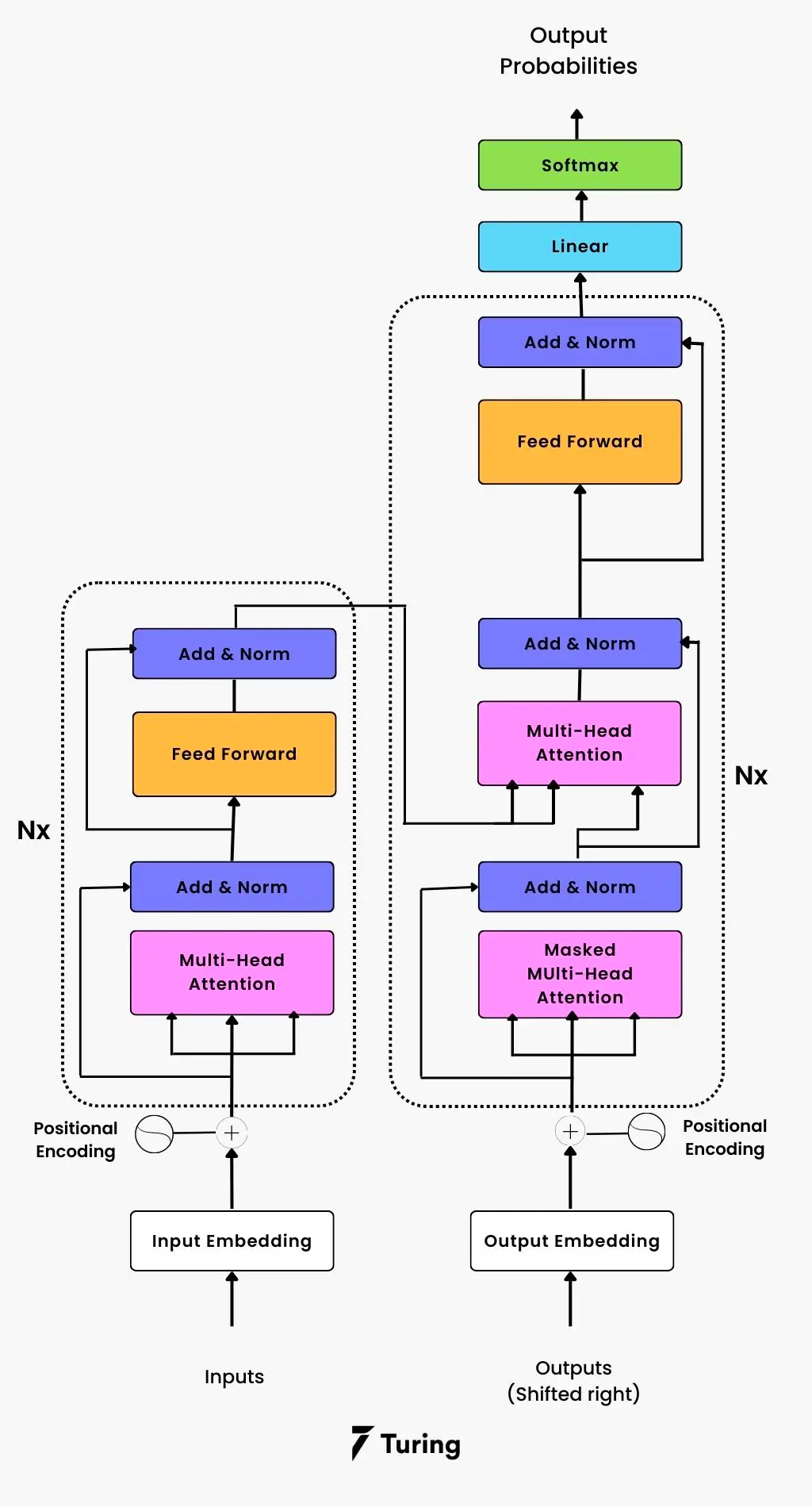
Figure 2: The Overall Architecture of Transformers
(https://www.turing.com/kb/brief-introduction-to-transformers-and-their-power)Because of its attention mechanism, transformers are inspired by the encoder-decoder design of RNNs. Sequence-to-sequence (seq2seq) activities can be handled while the sequential component is removed. A Transformer, unlike an RNN, does not process data sequentially, enabling more parallelisation and quicker training. The Transformer architecture includes several key components, such as multi-head attention, layer normalisation, and position-wise feedforward networks. These components help to improve the performance further.
Multi-head Attention: Multi-head attention is another vital component of the Transformer architecture. It enables the model to compute attention scores in multiple ways, allowing it to capture different types of relationships between words. (multi-head attention allows the model to attend to different input parts in multiple ways). Multi-head attention is a type of attention mechanism that allows the model to attend to different parts of the input in multiple ways. In the transformer architecture, multi-head attention is used to compute attention between the query and key vectors, with the output being a weighted sum of the value vectors.
The attention mechanism in multi-head attention is computed multiple times in parallel, with each computation being a ‘head’. Each head has its own set of parameters and can learn different patterns in the input. The outputs of the different heads are concatenated and passed through a linear layer to generate the final output. In multi-head attention, the input sequence is split into more minor sequences, and attention is computed separately for each sequence. This allows the model to capture different aspects of the input sequence, such as relationships between nearby words and relationships between words that are further apart in the sequence.
Multi-head attention can be broken down into three main steps: computing the queries, keys, and values; applying the attention mechanism to each head; and concatenating the outputs and passing them through a linear layer. The input is transformed into three matrices in the first step: the query matrix, the key matrix, and the value matrix. These matrices are then used as inputs for the attention mechanism. In the second step, the attention mechanism is applied to each head in parallel. Each head computes an attention weight matrix by taking the dot product of the query matrix and the key matrix and then applying a softmax function to normalise the weights. The attention weight matrix is then used to weight the value matrix, and the resulting weighted values are summed across the rows to produce the output of each head. In the third step, the outputs of the different heads are concatenated along the feature dimension, and the concatenated matrix is passed through a linear layer to generate the final output.
Positional Encoding: Positional encoding is used to provide the model with information about the position of each word in the input sequence. This is important because the self-attention mechanism and multi-head attention do not consider the order of the words in the sequence. Positional encoding is typically done by adding a fixed vector to each word representation based on its position in the sequence. This allows the model to capture the order of the words in the sequence while still allowing the self-attention mechanism and multi-head attention to capturing the complex relationships between words.
Feedforward Networks: The Transformer architecture includes feedforward networks, which transform the hidden representations of the input sequence. These networks typically consist of two fully connected layers with a ReLU activation function. The feedforward networks enable the model to learn non-linear transformations of the input sequence, which can be helpful in tasks such as text classification and machine translation.
Working of the Encoder: N layers comprise an encoder with two sublayers. A multi-head mechanism generates self-attention on the first sublayer. It has been proven that the multiple-head method produces h outputs concurrently while taking a (different) linear projection of the queries, keys, and values to produce the final output. Rectified Linear Units (ReLUs) activation is interleaved between two linear transformations in the second sublayer’s fully connected feed-forward network. The layers of the Transformer encoder translate each word in the input sequence individually. But to operate, each layer has its own set of weight (W1, W2) and bias (b1, b2) parameters. Each of these two sublayers also has a residual connection surrounding it. There is a normalisation layer, layernorm(. ), in addition to each sublayer, whose purpose is to normalise the sum computed between the sublayer input, X, and the sublayer output itself, sublayer(X). The Transformer deep learning architecture lacks an inherent mechanism to determine the relative arrangement of words because it does not employ recurrence. This information has been put into the embeddings using positional encodings. Sine and cosine functions with various frequencies create positional encoding vectors. Their dimension is the same as that of input embeddings. After that, positional information is added by adding them to the input embeddings.
Working of the Decoder: A decoder has N = 6 functional layers, with each layer comprising three sublayers: The decoder stack receives the previous output in the first sublayer, offers positional data, and applies self-attention to all of the heads. In contrast to encoders, which pay attention to every word regardless of order, decoders focus only on the words that come before them. The prediction for the word at position i therefore solely depends on the words that come before it in the sequence. The results of multiplying Q and K by a scale factor are overlaid with a mask by a multi-head attention mechanism, which implements numerous single attention functions concurrently. The second sublayer of the encoder employs a multi-head self-attention algorithm, much like the first sublayer did. This multi-head approach provides the decoders with queries from the previous sublayers of decoders and the output keys and values. It enables the decoder to focus on every word in the input string. Similar to the one used in the second sublayer of the encoder, a fully connected feed-forward network is implemented in the third layer. On the decoder side, a normalisation layer follows the first three sublayers. Additionally, there are lingering ties between them. The decoder also incorporates positional encodings into its input embeddings, similar to how the encoder did earlier.
Conclusion
We discussed the origins and evolution of large language models and how their underlying infrastructure (Transformers) differs from neural networks. LLMs indicate the dawn of a new era in AI and, perhaps, in the future of language itself. While Chat-GPT and LLMs have raised excitement in many quarters, there are misgivings and discordant voices from the AI community.
For all their potential, LLMs have defects that must be borne in mind. LLMs are trained on large amounts of text data, which can be biased towards certain demographics or viewpoints. This can result in the model generating biased or inappropriate responses to certain inputs. LLMs are incapable of true reasoning, meaning they cannot follow logical arguments or solve complex problems. This can limit their usefulness in certain applications, such as decision-making or critical thinking. LLMs may lack a basic understanding of common sense and general knowledge, resulting in nonsensical or inappropriate responses in certain situations.
You may also be interested in:
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
