Loading S3 Data into Your AWS SageMaker Notebook: A Guide

Amazon Web Services (AWS) offers a wide range of tools for data scientists, and two of the most powerful are S3 and SageMaker. S3 is a scalable storage solution, while SageMaker is a fully managed service that provides the ability to build, train, and deploy machine learning models. In this blog post, we’ll walk you through the process of loading data from S3 into a SageMaker notebook.

Table of Contents
- Prerequisites
- Step 1: Setting Up Your SageMaker Notebook
- Step 2: Accessing S3 Data from SageMaker
- Step 3: Loading Data into a Pandas DataFrame
- Step 4: Exploring Your Data
- Conclusion
Prerequisites
Before we start, make sure you have the following:
Step 1: Setting Up Your SageMaker Notebook
First, let’s set up your SageMaker notebook. Navigate to the AWS Management Console, select “SageMaker” from the “Services” dropdown, and then click on “Notebook instances” in the left-hand panel. Click “Create notebook instance”, give it a name, and select the instance type that suits your needs.
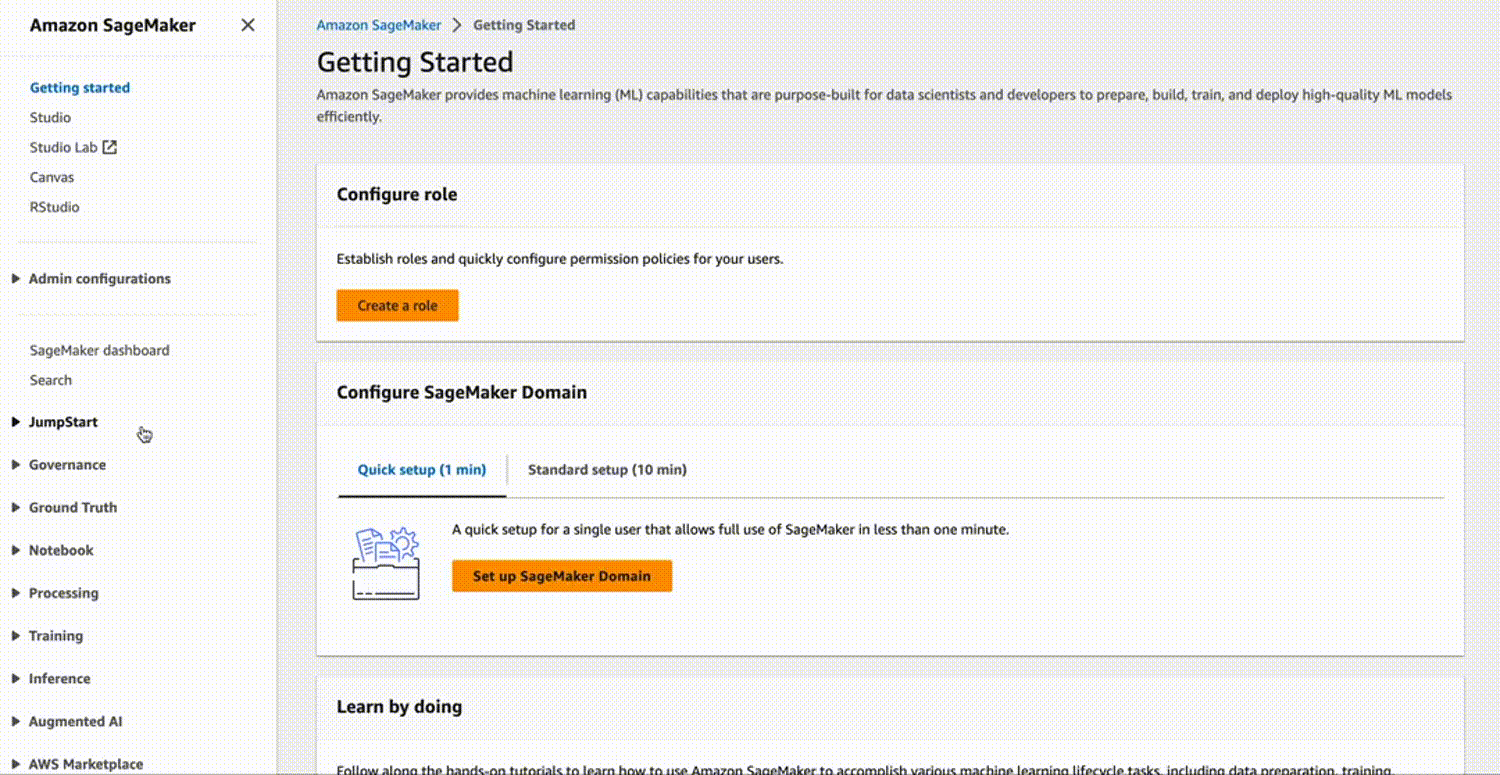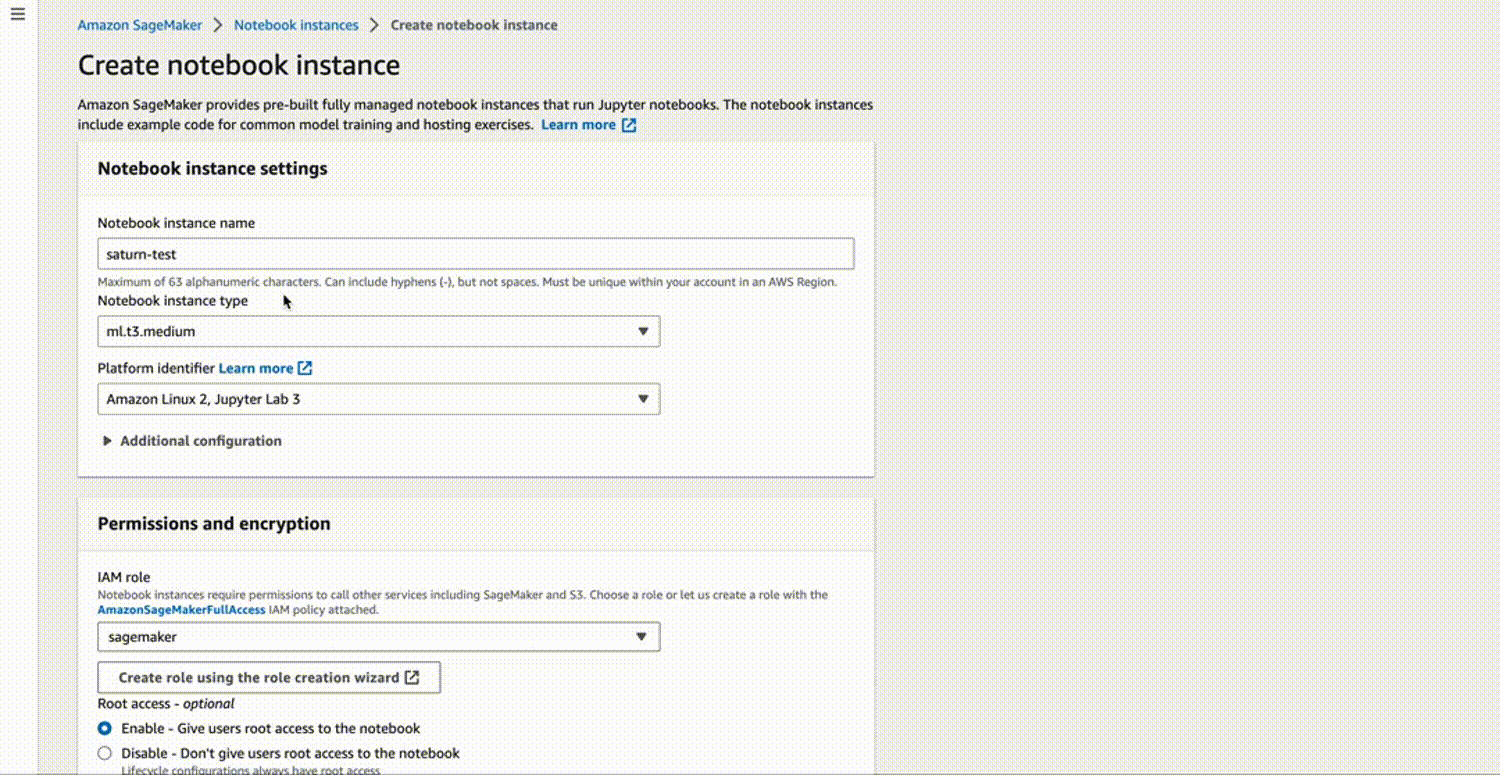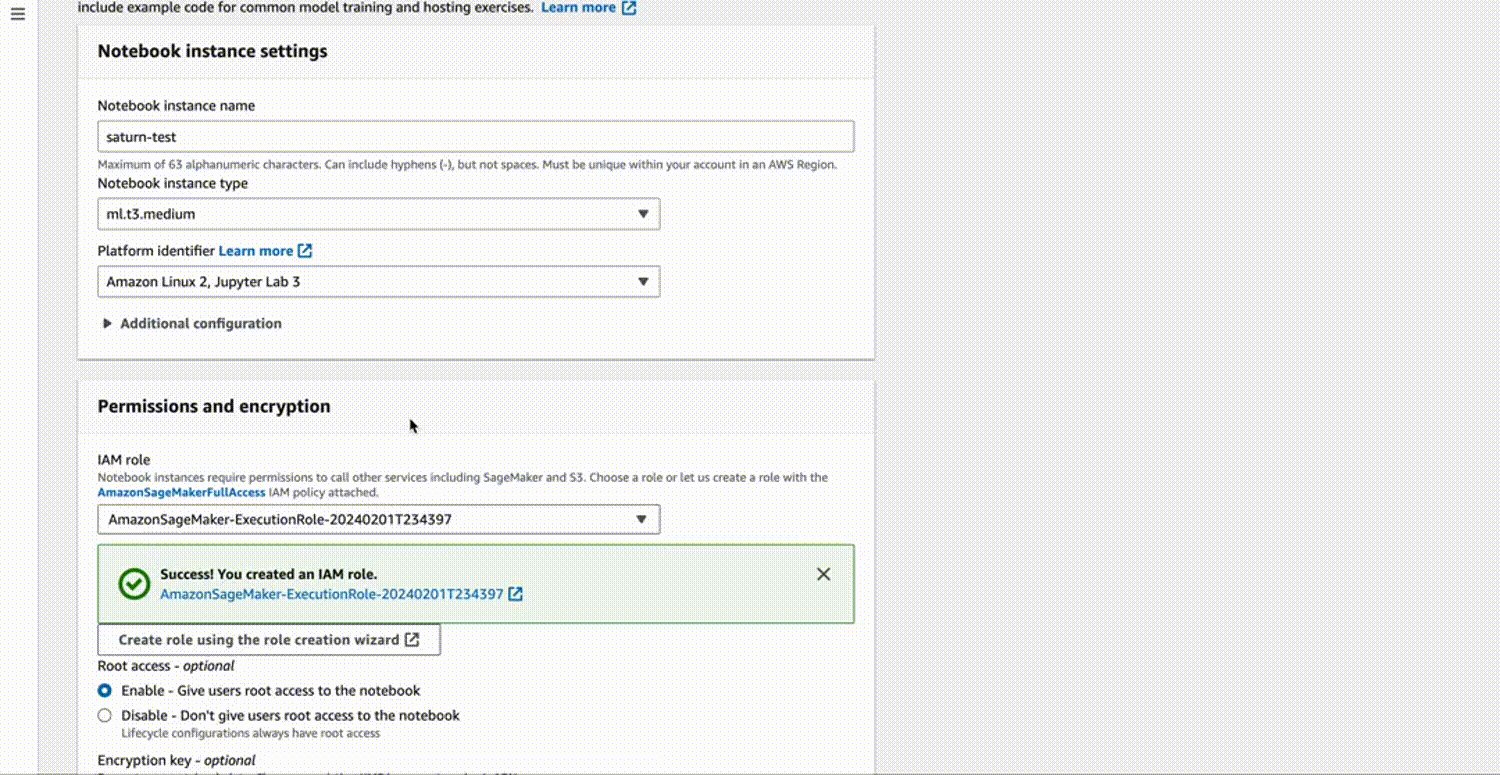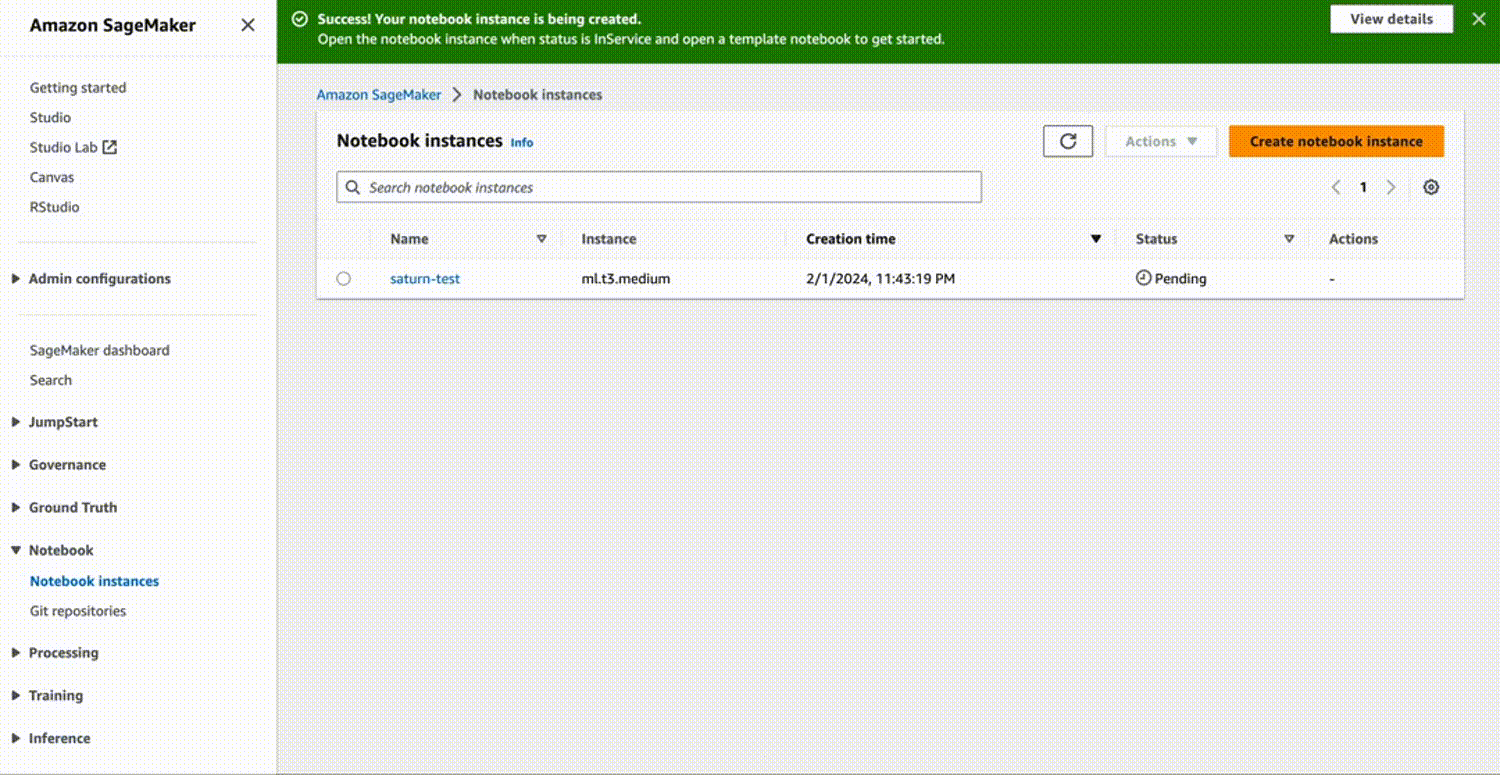
- **Notebook instance name**: Your choice
- **Notebook instance type**: ml.t2.medium (or any other as per your requirement)
For IAM role, you can either choose an existing role that has access to S3 or create a new one. If you’re creating a new role, ensure it has the necessary permissions to access S3.
Next, click on “Open Jupyter” to open a new Notebook for your experiment.

Step 2: Accessing S3 Data from SageMaker
Once your notebook is ready, open it and create a new Python 3 notebook. To access S3 data, we’ll use the boto3 library, which is the Amazon Web Services (AWS) SDK for Python. It allows Python developers to write software that makes use of services like Amazon S3 and Amazon EC2.
import boto3
s3 = boto3.resource('s3')
bucket_name = 'your-bucket-name'
file_name = 'your-file-name'
obj = s3.Object(bucket_name, file_name)
data = obj.get()['Body'].read()
In the above code, replace 'your-bucket-name' and 'your-file-name' with the name of your S3 bucket and the file you want to load, respectively.
The get()['Body'].read() function reads the file content.
Step 3: Loading Data into a Pandas DataFrame
Now that we have accessed the data, we can load it into a Pandas DataFrame for further analysis. The process will vary depending on the format of your data. Here’s how you can do it for a CSV file:
import pandas as pd
from io import StringIO
data_string = data.decode('utf-8')
data_file = StringIO(data_string)
df = pd.read_csv(data_file)
The StringIO function is used to convert the byte stream we got from S3 into a string stream that pandas can understand. Then, we use pd.read_csv to load the data into a DataFrame.
Step 4: Exploring Your Data
With your data loaded into a DataFrame, you can now use all the power of Pandas and other Python libraries to explore and analyze your data. For example, you can use the head() function to view the first few rows of your DataFrame:
print(df.head())
Output:
Product Region Quarter Revenue
0 Product C West Q2 123969
1 Product A West Q2 93001
2 Product C North Q3 126552
3 Product C North Q2 73897
4 Product A West Q3 118148
Conclusion
Loading S3 data into a SageMaker notebook is a common task for AWS-based data scientists. This guide has shown you how to do it step by step. Remember to replace the bucket and file names in the code with your own, and ensure your IAM role has the necessary permissions to access S3.
AWS SageMaker and S3 are powerful tools in the data scientist’s arsenal. By understanding how to use them together, you can streamline your data science workflows and focus on extracting insights from your data.
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
