Running Julia on Dask with Saturn Run

This article goes over dispatching parallel Julia code over dask clusters using Saturn Run. We use a toy example (fibonacci computation), but the approaches here can generalize to most real world problems.
Fibonacci with Julia
To start, I used Chat GPT to figure out how to write a Julia CLI for computing fibonacci. If you’re a Julia programmer you can do this from scratch. I am not, but I aspire to be one day.
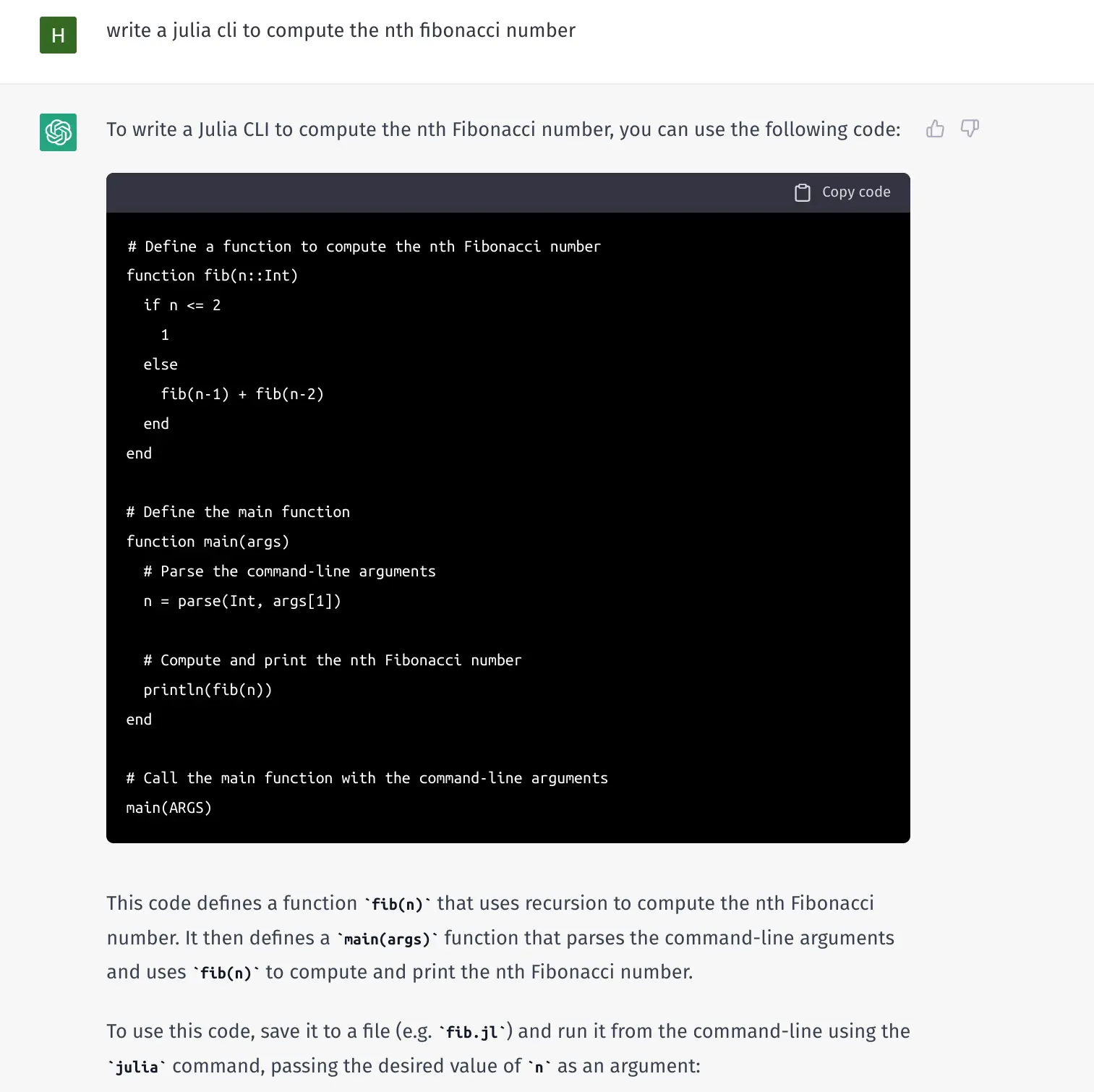
I saved this in Saturn Cloud under /home/jovyan/workspace/julia-example/fibonacci.jl
Dispatching Julia on Dask via Saturn Run
Saturn Run separates the configuration of the execution environment from the actual tasks. We used the following run.yaml
executor:
class_spec: DaskExecutor
scheduler_address: tcp://127.0.0.1:8786
results:
class_spec: LocalResults
path: /tmp/results/{name}
This configures:
- executor execute all jobs on a Dask Cluster running on localhost
- results store results (logs) to a local directory.
The following tasks.yaml configures the work to be done.
tasks:
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 12
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 30
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 5
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 13
These can be dispatched with
To execute this - I create a conda environment with the following packages:
name: saturn_run
channels:
- defaults
- conda-forge
dependencies:
- [python](https://saturncloud.io/glossary/python)=3.9
- bokeh
- dask=2022.9.0
- distributed=2022.9.0
- pip
- python-dotenv
- boto3
- ruamel.yaml
- pip:
- flake8
- black
- isort
- pytest
- pylint
- mypy
- bandit
- pytest-cov
- pytest-xdist
- pylint
- mypy
- types-requests
- bandit
- psutil
- boto3_type_annotations
- dask-saturn
- git+https://github.com/saturncloud/saturn-run.git
I also create a Dask LocalCluster by starting the scheduler in one terminal
$ dask-scheduler
And the worker in another
$ dask-worker tcp://127.0.0.1:8786
Finally - dispatch saturn run
$ saturn run run.yaml tasks.yaml --prefix compute-fib
Here, --prefix compute-fib tells saturn run to construct a name using that prefix and timestamp, resulting in the following output
INFO:root:creating run config with name: compute-fib-2022-12-14T06:25:46.423392+00:00
INFO:numexpr.utils:NumExpr defaulting to 4 threads.
INFO:root:executing 0 with key compute-fib-2022-12-14T06:25:46.423392+00:00/0/00441665a68d283d0ec1cb4cb99758e3
INFO:root:executing 1 with key compute-fib-2022-12-14T06:25:46.423392+00:00/1/84dd3e7d5ce08856c382d49e7ec49cb8
INFO:root:executing 2 with key compute-fib-2022-12-14T06:25:46.423392+00:00/2/49da0d783f7dca54936e94b481701f66
INFO:root:executing 3 with key compute-fib-2022-12-14T06:25:46.423392+00:00/3/d544bcf9089b16a0f150917d6483738e
INFO:root:finished srun/compute-fib-2022-12-14T06:25:46.423392+00:00/0
INFO:root:finished srun/compute-fib-2022-12-14T06:25:46.423392+00:00/2
INFO:root:finished srun/compute-fib-2022-12-14T06:25:46.423392+00:00/3
INFO:root:finished srun/compute-fib-2022-12-14T06:25:46.423392+00:00/1
Julia Task Output
The above is just the stdout of the terminal dispatch calls. Most of the actual output is written to disk. Note in the above output, that --prefix compute-fib resulted in the run being named compute-fib-2022-12-14T06:25:46.423392+00:00. Since the LocalResults object was templated with {name} I can find the results in
$ ls /tmp/results/compute-fib-2022-12-14T06\:25\:46.423392+00\:00/
0 1 2 3
Each task was written to a directory. Each task has been given a name since one wasn’t specified. Alternatively, names can be specified in tasks.yaml
tasks:
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 12
name: run1
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 30
name: run2
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 5
name: run3
- command: julia /home/jovyan/workspace/julia-example/fibonacci.jl 13
name: run4
Within a one of the directories are 4 files:
total 12K
-rw-rw-r-- 1 jovyan jovyan 0 Dec 14 06:25 stderr
drwxrwxr-x 2 jovyan jovyan 6 Dec 14 06:25 results
-rw-rw-r-- 1 jovyan jovyan 7.1K Dec 14 06:25 stdout
-rw-rw-r-- 1 jovyan jovyan 1 Dec 14 06:25 status
The status code of the pid is written to status. In our case since every task succeeded, all of the status files have a 0 written to them. But if the script had errored, the non-zero status code would have been written there. All of the output goes to stdout and stderr. Looking at stdout
calling fibonacci with 2
calling fibonacci with 3
calling fibonacci with 2
calling fibonacci with 1
calling fibonacci with 4
calling fibonacci with 3
calling fibonacci with 2
calling fibonacci with 1
calling fibonacci with 2
The 12th number in the Fibonacci sequence is 144
The results directory is empty. saturn run does not automaticaly dump any data into the results directory - instead of injects a RESULTS_DIR environment variable, that your script can use to write results.
Outputing all this diagnostic information to disk is important. This makes it possible to see which tasks failed, look at the stack traces of failed tasks, and re-try falures. To re-try failures - I just need to create a new tasks.yaml with the failed commands, and re-submit
Collecting Runs
When a run is executed, it is dispatched to the cluster, and then the individual jobs are monitored. This process of monitoring and waiting for jobs to complete is called collect. If we kick off a run, and we hit ctrl-c before the job completes, we can re-connect to it with saturn collect.
saturn run is dispatching, and then collecting the results.
We can re-connect to an existing run with saturn collect.
$ saturn collect julia-example/local-run.yaml --name compute-fib-2022-12-14T06:47:31.316608+00:00
INFO:root:creating run config with name: compute-fib-2022-12-14T06:47:31.316608+00:00
INFO:numexpr.utils:NumExpr defaulting to 4 threads.
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/3
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/1
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/2
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/0
Note - that tasks.yaml is not needed to collect, but run.yaml is. This is because the state is often stored on the cluster, and run.yaml is what defines the cluster. In addition, if names were generated via –prefix, you will need the generated name in order to collect.
Whenever possible, saturn run is architected to make collecting un-necessary. However some configurations we may have in the future ( for example collecting results from a cluster to local disk ) will require the collection process.
This collection process does things, like clean up artifacts on the cluster, as well as dispatch subsequent jobs if your jobs have dependencies - a topic for a future blog post.
Running Julia on a multi-node cluster
Running on a multi-node cluster requires me to have a networked location for storing results (S3). I also use SaturnCluster in order to dispatch the same code across multiple machines. The fibonacci.jl script I ran only exists on my local machine. It does not exist on the remote cluster I spun up. saturn run has a concept of file_syncs which can be used to sync directories across from the client to server.
executor:
class_spec: DaskExecutor
cluster_class: SaturnCluster
results:
class_spec: S3Results
s3_url: s3://saturn-internal-s3-test/saturn-run-2022.12.13/{name}/
file_syncs:
- src: /home/jovyan/workspace/julia-example/
It’s intentional that the run configuration (run.yaml) is kept separate from task definitions (tasks.yaml) so that you can easily switch back and forth between dispatching to a multi-node cluster vs dispatching local.
When I dispatch this run, the first thing that happens is the multi-node cluster is provisioned
INFO:root:creating run config with name: compute-fib-2022-12-14T06:47:31.316608+00:00
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Starting cluster. Status: pending
INFO:dask-saturn:Cluster is ready
INFO:dask-saturn:Registering default plugins
INFO:numexpr.utils:NumExpr defaulting to 4 threads.
INFO:dask-saturn:Cluster is ready
INFO:dask-saturn:Registering default plugins
INFO:dask-saturn:Cluster is ready
INFO:dask-saturn:Registering default plugins
Then, my julia-example directory is synced to the remote machines:
./
./fibonacci.jl~
./run.yaml
./#run.yaml#
./run.yaml~
./fibonacci.jl
./local-run.yaml~
./task.yaml
./local-run.yaml
Finally the jobs are executed:
INFO:dask-saturn:Cluster is ready
INFO:dask-saturn:Registering default plugins
INFO:root:executing 0 with key compute-fib-2022-12-14T06:47:31.316608+00:00/0/00441665a68d283d0ec1cb4cb99758e3
INFO:root:executing 1 with key compute-fib-2022-12-14T06:47:31.316608+00:00/1/84dd3e7d5ce08856c382d49e7ec49cb8
INFO:root:executing 2 with key compute-fib-2022-12-14T06:47:31.316608+00:00/2/49da0d783f7dca54936e94b481701f66
INFO:root:executing 3 with key compute-fib-2022-12-14T06:47:31.316608+00:00/3/d544bcf9089b16a0f150917d6483738e
INFO:dask-saturn:Cluster is ready
INFO:dask-saturn:Registering default plugins
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/0
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/2
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/3
INFO:root:finished srun/compute-fib-2022-12-14T06:47:31.316608+00:00/1
My logs are present in S3
$ aws s3 ls s3://saturn-internal-s3-test/saturn-run-2022.12.13/compute-fib-2022-12-14T06:47:31.316608+00:00/
PRE 0/
PRE 1/
PRE 2/
PRE 3/
The RESULTS_DIR can still be used in the multi-node case. RESULTS_DIR will be presented as a local directory on the remote machine, which will be synchronized with S3 when complete. On infrastructure with some sort of networked file system, the same LocalResults object can be used instead of S3Results.
Conclusion
saturn run is an easy way to dispatch command line scripts that handles all the boiler plate of tracking job status, logs and output. This example demonstrates how it can be used to parallelize Julia code, however we have also used it to parallelize R, as well as Python code.
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
