How to Write Data To Parquet With Python

Photo credit: Google DeepMind via UnSplash
Introduction
Apache Parquet is a language-agnostic, open-source file format that was built to handle flat columnar storage data formats. Parquet operates well with complex data in large volumes. It is known for its both performant data compression and its ability to handle a wide variety of encoding types.
Parquet files are highly compatible with OLAP systems and provide an efficient way to store and access data hence they are very useful for big data processing
Benefits of Parquet
Column-oriented databases such as AWS Redshift Spectrum bill by the amount of data scanned per query hence storing data in parquet files with partitioning and compression lowers overall costs and improves performance.
Increased data throughput and performance using techniques like data skipping, whereby queries that fetch specific column values need not read the entire row of data.
Saves on cloud storage space using highly efficient column-wise compression and flexible encoding schemes for columns with different data types.
Parquet is suitable for storing large datasets, including structured data tables, images, videos, and documents.
In this blog post, we’ll discuss how to define a Parquet schema in Python, then manually prepare a Parquet table and write it to a file, how to convert a Pandas data frame into a Parquet table, and finally how to partition the data by the values in columns of the Parquet table.
Prerequisites
Python 3.6 or later
PyArrow library
Pandas library
PyArrow is a Python library providing a Pythonic interface to Apache Arrow, an in-memory columnar data format. It also provides a fast and efficient way to read and write Parquet files.
Pandas is a Python library that provides easy-to-use open-source data analysis tools and data structures.
To install the Pyarrow package, you can run the following command to install binary wheels from PyPI with pip:
pip install pyarrow
Importing the libraries
We have to import PyArrow and its Parquet module. Additionally, we import Pandas library as we will use it in our examples.
# Importing libraries
import [pandas](https://saturncloud.io/glossary/pandas) as pd
import pyarrow as pa
import pyarrow.parquet as pq
How to define a schema
You can let the column types be inferred automatically or you can define a schema. In this section, you will learn how to define a schema using an imaginary scenario.
Imagine that you want to store weather data in a Parquet file. You have data for various cities, including the city name, the date and time of the measurement, the temperature in Celsius, and the atmospheric pressure in kilopascals. The following schema describes a table which contains all of that information.
weather_schema = pa.schema([
('city', pa.string()),
('measurement_time', pa.timestamp('ms')),
('temperature', pa.float32()),
('atmospheric_pressure', pa.float32())
])
Columns and batches
A batch is a group of arrays with similar lengths. Each array only has information from a single column. The schema you just developed aggregates the columns into a batch.
From the example above, we will store three values in every column. Here are the values:
# Create PyArrow arrays for weather data
cities = pa.array(['New York', 'London', 'Tokyo'], type=pa.string())
measurement_times = pa.array([
datetime(2022, 5, 1, 12, 0, 0),
datetime(2022, 5, 1, 13, 0, 0),
datetime(2022, 5, 1, 14, 0, 0)
], type=pa.timestamp('ms'))
temperatures = pa.array([20.5, 15.2, 23.1], type=pa.float32())
pressures = pa.array([101.5, 99.2, 100.1], type=pa.float32())
# Create a PyArrow RecordBatch from the arrays
batch = pa.RecordBatch.from_arrays(
[cities, measurement_times, temperatures, pressures],
names=weather_schema.names
)
Tables
To define a single logical dataset, we use a Table. It can involve several batches. The write_table function can be used to write a table, a type of structure, to a file.
table = pa.Table.from_batches([batch])
pq.write_table(table, 'test/weather.parquet')
When you call the write_table function, it will create a single parquet file called weather.parquet in the current working directory’s “test” directory.
Writing Pandas data frames
In the above section, we’ve seen how to write data into parquet using Tables from batches. You can define the same data as a Pandas data frame instead of batches. It may be easier to do it this way because you can generate the data row by row, which is the most preferable way by many programmers.
# Create a Pandas data frame with some sample weather data
df = pd.DataFrame({
'city': ['New York', 'London', 'Tokyo'],
'measurement_time': ['2022-05-01 12:00:00', '2022-05-01 12:00:00', '2022-05-01 12:00:00'],
'temperature': [20.5, 15.2, 23.1],
'atmospheric_pressure': [101.5, 99.2, 100.1]
})
# Convert the Pandas DataFrame to a PyArrow table
table = pa.Table.from_pandas(df, schema=weather_schema)
# Write the PyArrow table to a Parquet file
pq.write_table(table, 'test/weather_data.parquet')
In this example, we create a Pandas DataFrame with some sample weather data and convert it to a PyArrow table using the Table.from_pandas() function. We then write the PyArrow table to a Parquet file named 'weather_data.[parquet](https://saturncloud.io/glossary/parquet)' using the pq.write_table() function.
Data partitioning
Data partitioning is a technique that involves splitting large datasets into smaller, more manageable subsets based on certain criteria. Partitioning can be very useful when working with large datasets because it allows you to process only the data you need, rather than reading in and processing the entire dataset simultaneously.
PyArrow provides a simple and efficient way to partition data when writing it to Parquet files.
Continuing with the weather data example from earlier, let’s say we want to partition our data by city. We can do this by using the write_to_dataset() method to write the data to a Parquet dataset with the city as the partition key.
# Define the output path for the Parquet dataset
output_path = 'test/weather_partitioned_data'
# Write the data to a Parquet dataset partitioned by city
pq.write_to_dataset(
table,
root_path=output_path,
partition_cols=['city']
)
When writing data to a partitioned dataset, PyArrow will automatically create a directory for each distinct value of the partition column.
In this case, PyArrow will create three directories within the ‘weather_partitioned_data’ directory, one for each city in our dataset (‘New York’, ‘London’, and ‘Tokyo’). Within each city directory, PyArrow will create a Parquet file containing only the data for that city. This makes it easy to read and process only the data you need, without having to load and process the entire dataset at once.
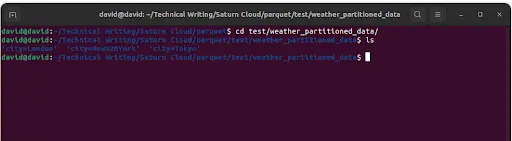
Partitioning can be done based on any column in the dataset, and multiple columns can be used to define the partition key. By partitioning your data, you can significantly improve the performance of data processing and analysis, especially when working with large datasets.
Conclusion
In this article, we learned how to write data to Parquet with Python using PyArrow and Pandas. We defined a simple Pandas DataFrame, the schema using PyArrow, and wrote the data to a Parquet file. Parquet provides a highly efficient way to store and access large datasets, which makes it an ideal choice for big data processing. If you’d like to try this right away, get started on Saturn Cloud for free.
You may also be interested in:
- How to change column type in Pandas
- How to reorder columns in Pandas
- How to drop Pandas DataFrame rows with NAs in a specific column
- How to get a list of column names from a Pandas DataFrame
- How to count rows in Pandas
- How to delete a Pandas DataFrame column
- How to rename DataFrame columns in Pandas
- How to select rows by column value in Pandas
- How to iterate over rows in Pandas
- Dask DataFrame is not Pandas
- Dask and pandas: There’s No Such Thing as Too Much Data
- Handy Dandy Guide to Working With Timestamps in pandas
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
