How to Set Up Luigi

Introduction
Automating different workflows is necessary with most projects and processes. For example, getting data from one point to another (ETL/ELTs), running machine learning models, or general workflow automation. In this article, we will setup Luigi: a tool that can automate workflows and much more. We will use it to orchestrate downloading a CSV file, transforming it, and warehousing it.

What is Luigi?
Luigi is an open-source Python package for building complex and long-running data pipelines and scheduling and monitoring tasks or batch jobs. It was developed by Spotify to build and execute data pipelines and is now being maintained by the open-source community.
Luigi’s is much like Airflow because it has a simple framework for managing and scheduling long-running batch processes or data workflows, making it easy to build data pipelines that can handle large volumes of data complete with Directed Acyclic Graphs (DAGs) to aid developers to schedule and monitor sets of tasks or batch jobs with the Luigi Task Visualiser.
Uses for Luigi
For small-scale data pipelines with a few tasks, you can always run them manually. However, as the tasks and dependabilities in data pipelines grow, running them manually becomes a hassle. With Luigi, data engineers or anyone with a complex pipeline or process can automate running a pipeline complete with dependencies that track and log errors.
With Luigi, you can define tasks that perform specific data processing operations, such as ingesting data from different sources, transforming data, and loading the data to a destination. These tasks can be linked into workflows, defining the order in which the tasks should be executed and their dependencies.
Setting up Luigi
You can set up Luigi in a few simple steps. Here is an overview of the process:
Install Luigi: You can install Luigi using pip, the Python package manager.
Open your terminal and type the following command:
pip install luigi
Creating a Task
A Luigi pipeline contains a bunch of tasks which are Python classes that inherit from a luigi.Task class. In the sample below, we would create a pipeline that loads a CSV from the web, does basic transformation, and loads it into an Elephantsql Database.
A Luigi Task has 3 components for each Class:
def requires: Which holds the dependencies for the current task. This holds all the dependencies the current task requires to run
def output(self): Any output the current task will return is defined here. When a Luigi task is started, it checks if output already exists in the path specified; if it does, it will assume the task has been run and will skip it
def run(self): This contains the actual logic and code of the task, this does any ingestion or runs the long-running code.
We would create a python file and write the following code
import luigi
import [pandas](https://saturncloud.io/glossary/pandas) as pd
from sqlalchemy import create_engine
url = "https://thedocs.worldbank.org/en/doc/92631f5aa8ecaed440d9b2e0ab8810e7-0050062021/original/Global-Financial-Development-Database-11-1-2021.xlsx"
class WriteCSVToDatabase(luigi.Task):
"""
A Luigi task to write a CSV file to ElephantSQL database
"""
database_name = luigi.Parameter()
user_name = luigi.Parameter()
database_password = luigi.Parameter()
def requires(self):
"""
No dependencies for this task so we can return [] or None
"""
return []
def output(self):
"""
Returns the target output for this task. No output is required for this task
"""
return None
def run(self):
database_password = self.database_password
user_name = self.user_name
database_name = self.database_name
"""
Contains the logic of the Task,
"""
# Read the CSV file, transform by dropping the first 2 rows and ingesting the data
data = pd.read_excel(url, sheet_name =2, nrows = 1000)
transformed_data = data[2:]
engine = create_engine(f'''postgresql://{user_name}:{database_password}@trumpet.db.elephantsql.com/{database_name}''')
transformed_data.to_sql('luigi_data', engine, if_exists='replace', index = False, method = 'multi')
if __name__ == '__main__':
luigi.run()
Running the Luigi scheduler: The Luigi scheduler is the component of Luigi that manages the execution of tasks. You can run the scheduler by typing the following command in your terminal:
luigid

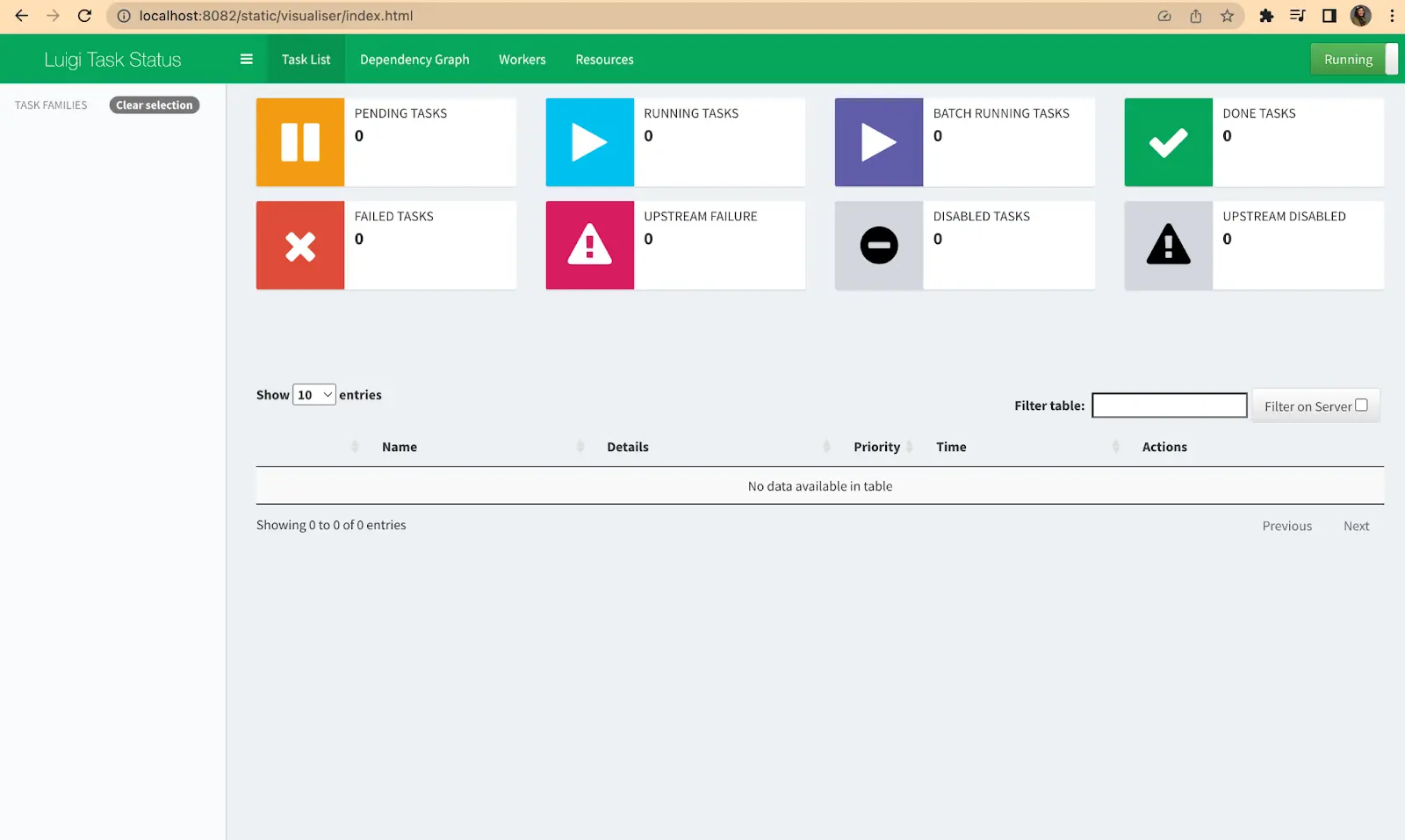
This will start the scheduler, and you can access its web interface by navigating to http://localhost:8082 on your browser; it should look like this:
Running the Task: You can run the task(s) using your terminal, navigate to the path where the python file is saved and use the syntax below to run the python file
PYTHONPATH='.' luigi --module my_module MyTask --parameter foo
In our case with the luigi_text.py file we created we run the bash script below in our terminal
PYTHONPATH='.' luigi --module luigi_test WriteCSVToDatabase --WriteCSVToDatabase-database-name ureqkjny --WriteCSVToDatabase-user-name ureqkjny --WriteCSVToDatabase-database-password ogYBbg-3MOmYTbVOSUZ-AoZkyYsjH40K
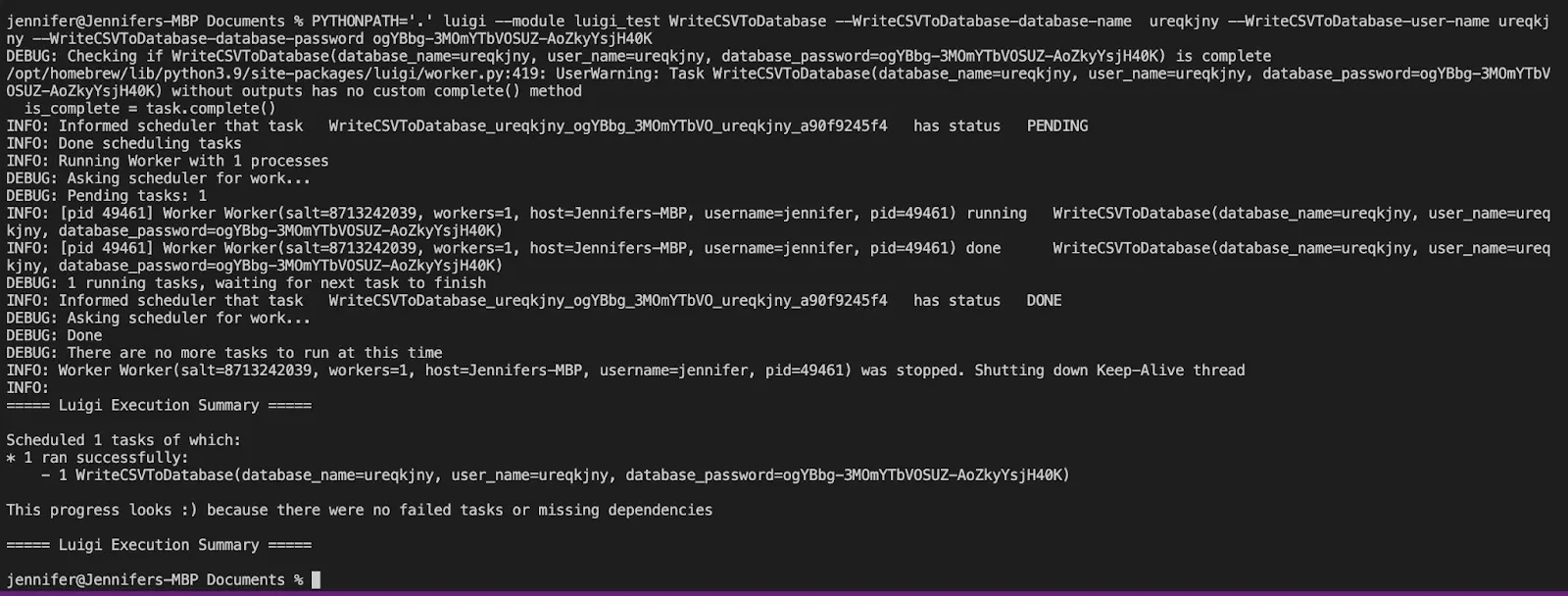
A success message looks like this and our luigi_test.py file ran successfully
Conclusion
Luigi is a powerful tool for automating complex data workflows and batch processes. With Luigi, developers can define tasks and dependencies, schedule and monitor sets of tasks, and track and log errors, making handling large volumes of data easier. Setting up Luigi is relatively straightforward, and developers can create pipelines by defining tasks that perform specific data processing operations. By following the steps outlined in this article, developers can get started with Luigi and begin automating their workflows today.
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
