Finetune Llama with Affordable On-Demand H100 and H200 GPU Instances

Accessing enterprise-grade GPUs like NVIDIA H100s and H200s has traditionally meant choosing between expensive on-demand pricing or navigating long reservation queues with cloud providers like AWS. Through Saturn Cloud’s MLOps platform with Nebius’ flexible GPUs, teams can now get instant access to high-performance GPUs at a significantly lower cost, all without compromising on availability or flexibility.
ML teams can spin up distributed GPU clusters in seconds using familiar tools like Dask, Ray, or PyTorch Distributed. With dynamic scaling built in, workloads can automatically expand during peak demand and contract when idle, improving both efficiency and cost-effectiveness without the need for manual provisioning or DevOps overhead.
With this infrastructure in place, running large-scale training workloads—such as fine-tuning LLaMA models—becomes not only feasible but also efficient. The combination of instant access to H100s and H200s and Saturn Cloud’s managed environments removes the usual setup friction, allowing teams to focus directly on experimentation and iteration. Below is an example of how you can fine-tune a LLaMA model using this setup.
Finetune Llama-3.1-8B-Instruct on Medical Data
In this demo, we’ll be fine-tuning Llama-3.1-8B-Instruct with the medical-o1-reasoning-SFT, a public dataset of medical conversations. Before we get started, let’s quickly spin up a Saturn Cloud resource. Simply go to your dashboard’s resource tab and click “New Python Server.”
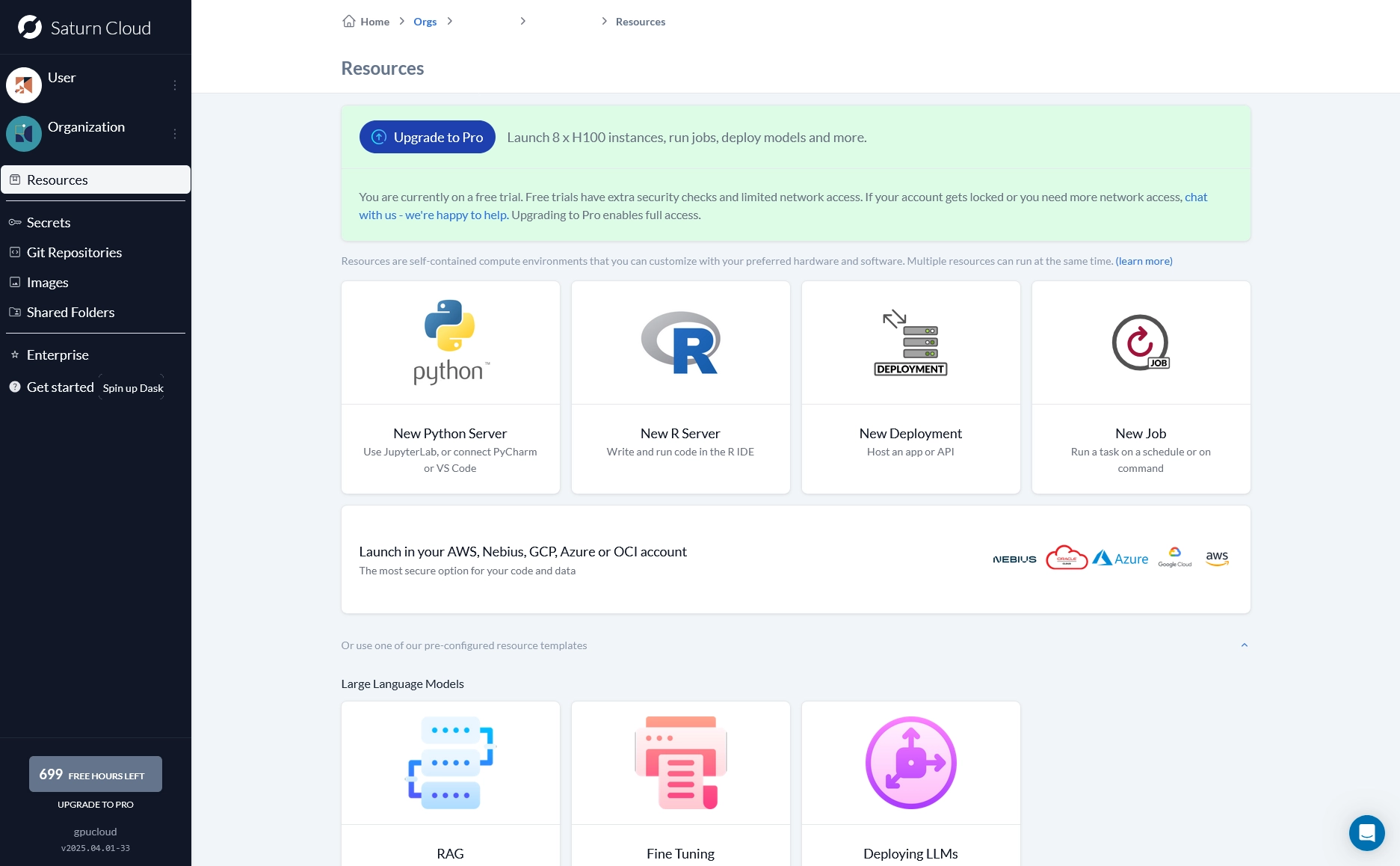
Next, name your resource, select the GPU instance and the amount of GPUs and disk space you would like, and add unsloth and matplotlib into the pip dependencies. Click submit.
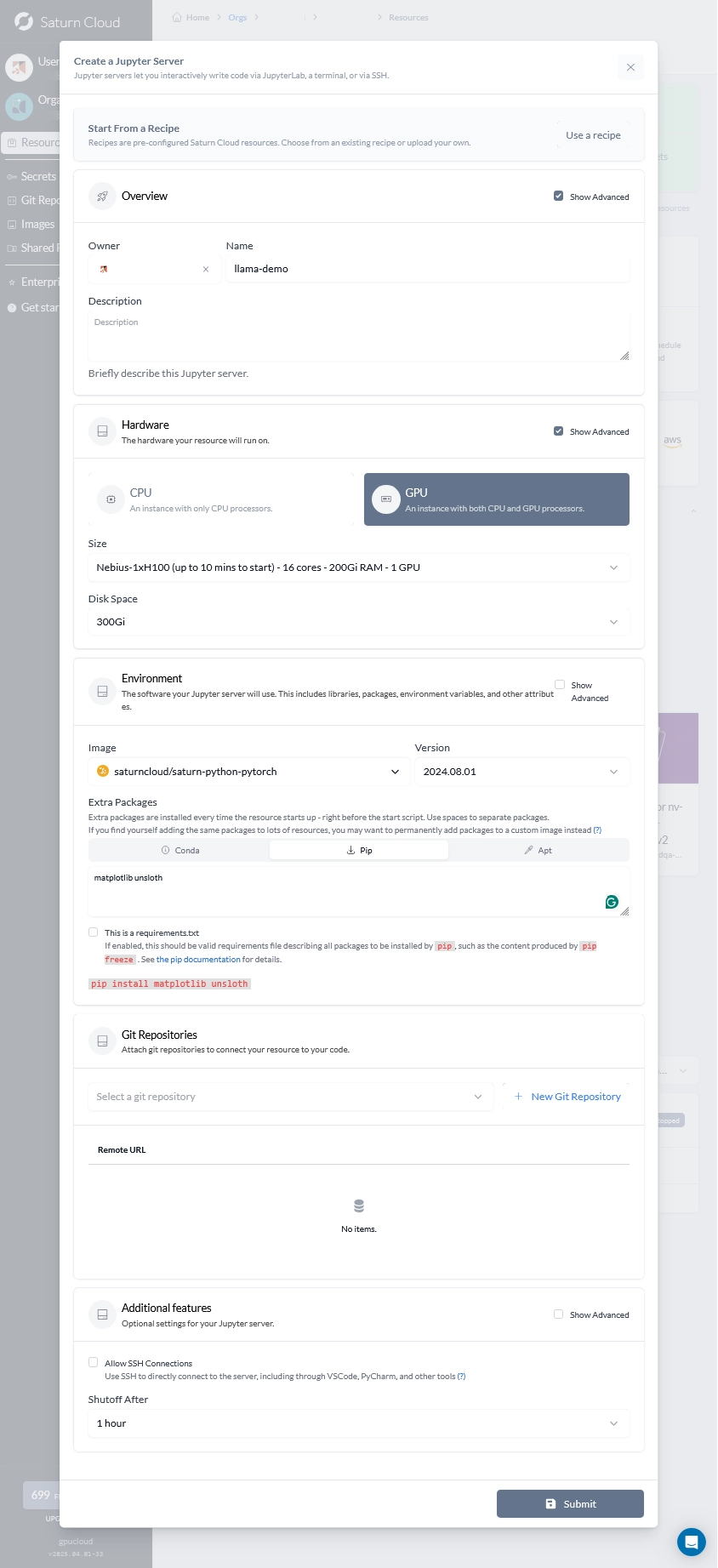
Once the resource has been made, simply click the start button. Once your resource has been successfully provisioned, follow the URL to open up the Jupyter instance. It’s as quick and easy as that!
Testing Out-of-Box Outputs
Before we begin our finetuning, we can quickly pass a prompt to Llama using its pretrained weights to use as a reference output. The goal is to then fine-tune this model and run this same prompt through our fine-tuned Llama model. To initialize Llama, simply use `unsloth` to we can quickly import Llama using unsloth and then set the model to be used for inference.
from unsloth import FastLanguageModel
from transformers import AutoTokenizer, TextStreamer, StoppingCriteria, StoppingCriteriaList
import torch
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit")
# Load 4-bit quantized model
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
max_seq_length=2048,
dtype=None, # Auto
load_in_4bit=True # Use 4-bit quantization
)
# Enable faster inference
FastLanguageModel.for_inference(model)
Next, we’ll set our stop token and system prompt.
class StopOnTokens(StoppingCriteria):
def __init__(self, stop_strings, tokenizer):
self.stop_token_ids = [tokenizer.encode(s, add_special_tokens=False) for s in stop_strings]
def __call__(self, input_ids, scores, **kwargs):
for stop_id_seq in self.stop_token_ids:
if input_ids[0][-len(stop_id_seq):].tolist() == stop_id_seq:
return True
return False
stop_strings = ["### Instruction:"]
stopping_criteria = StoppingCriteriaList([StopOnTokens(stop_strings, tokenizer)])
alpaca_prompt = """You are a compassionate medical assistant. Provide clear and accurate medical advice based on the patient’s input and strong reasoning.
### Instruction:
{}
### Input:
{}
### Response:
"""
Finally, we can set our input prompt and pass these inputs to the model.
instruction = "What drug is most likely responsible for a 2-year-old child developing bone pain, vomiting, and features of increased intracranial pressure following excessive medication, with no presence of fever?"
input_context = ""
prompt_text = alpaca_prompt.format(instruction, input_context)
inputs = tokenizer([prompt_text], return_tensors="pt").to("cuda")
output = model.generate(
**inputs,
max_new_tokens=512,
stopping_criteria=stopping_criteria,
eos_token_id=tokenizer.eos_token_id,
streamer=text_streamer,
)
Output
<|begin_of_text|>You are a compassionate medical assistant. Provide clear and accurate medical advice based on the patient’s input and strong reasoning.
### Instruction:
What drug is most likely responsible for a 2-year-old child developing bone pain, vomiting, and features of increased intracranial pressure following excessive medication, with no presence of fever?
### Input:
### Response:
To address the scenario presented, let's consider the common medications that could cause such symptoms in a 2-year-old child. The symptoms described, including bone pain, vomiting, and features of increased intracranial pressure, are indicative of a condition known as "rebound" or "withdrawal" symptoms, often associated with medications that have a high dependency potential or are used to manage pain or other conditions.
Given the age of the child and the symptoms, one of the most likely culprits is acetaminophen (paracetamol). However, the symptoms described are more severe and not typical of acetaminophen overdose. Another possibility is that the child has been exposed to a medication that has a high risk of causing withdrawal or rebound effects, such as opioids.
But considering the child's age and the symptoms, a more likely scenario is that the child has been exposed to a medication that is known to cause these symptoms in children, such as ibuprofen or acetaminophen, but in a context of overdose or overuse leading to withdrawal symptoms.
The key point here is the presence of symptoms that suggest withdrawal or rebound, which can occur with certain medications, especially when used excessively or in high doses.
However, without more information on the exact medication, dosage, and duration of use, it's challenging to pinpoint the exact drug responsible. It's also crucial to note that certain medications can have a cumulative effect over time, especially in young children, leading to symptoms like those described.
In any case, the immediate concern is the child's well-being, and medical attention should be sought as soon as possible to ensure proper diagnosis and treatment. A pediatrician or a medical professional experienced in pediatric care should be consulted to provide a definitive diagnosis and appropriate management plan. They can assess the child's condition, consider the potential medications and their effects, and provide guidance on the best course of action.<|eot_id|>
Loading in Llama for Fine-tuning
Next, load up a new Jupyter notebook. We will then load in Llama once more, but without setting the model to inference mode.
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None # None for auto detection. Float16 for Tesla T4, V100,
# Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be
# False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit
)
Next, LoRA is applied to the model, targeting specific projection layers with a rank of 16 and alpha scaling. Gradient checkpointing is enabled using the “unsloth” method to save memory and allow longer context lengths. This setup optimizes the model for efficient fine-tuning with reduced VRAM usage.
model = FastLanguageModel.get_peft_model(
model,
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
Load in Data
After our model has been loaded in, download FreedomIntelligence/medical-o1-reasoning-SFT from HuggingFace and preprocess the inputs before training. Before loading the dataset for training, it’s important to analyze the token length distribution. This helps strike a balance between capturing most of the data without wasting computation on overly long sequences that are rare, allowing us to choose an optimal max token length for efficient training.
from datasets import load_dataset
import matplotlib.pyplot as plt
def get_token_length_distribution(tokenizer):
raw_dataset = load_dataset("FreedomIntelligence/medical-o1-reasoning-SFT", "en_mix", split="train", trust_remote_code=True)
def format_to_alpaca(example):
prompt = (
"Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n"
f"### Instruction:\n{example['Question']}\n\n"
f"### Input:\n{example['Complex_CoT']}\n\n"
f"### Response:\n{example['Response']}"
)
return {"text": prompt}
formatted_dataset = raw_dataset.map(format_to_alpaca)
token_lengths = []
for example in formatted_dataset:
tokens = tokenizer(example["text"], padding=False, truncation=False)
token_lengths.append(len(tokens["input_ids"]))
plt.hist(token_lengths, bins=50)
plt.xlabel("Token length")
plt.ylabel("Number of samples")
plt.title("Token length distribution in dataset")
plt.show()
token_lengths_sorted = sorted(token_lengths)
print(f"Max token length: {max(token_lengths)}")
print(f"Median token length: {token_lengths_sorted[len(token_lengths)//2]}")
print(f"90th percentile length: {token_lengths_sorted[int(len(token_lengths)*0.9)]}")
# Example usage:
get_token_length_distribution(tokenizer)
Output
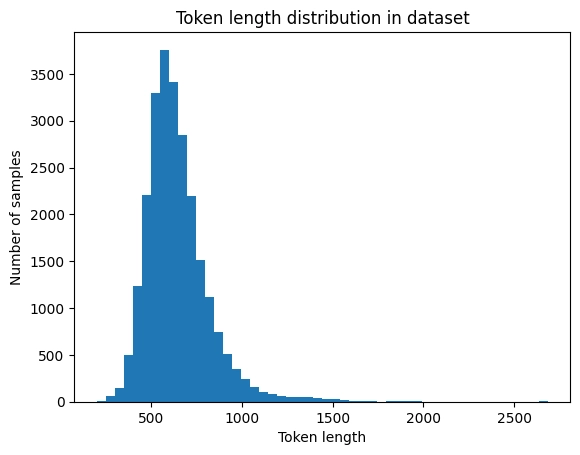
Max token length: 2685
Median token length: 617
90th percentile length: 853
Given the token length of the dataset, the majority of conversations are around 900 tokens. Prepare the dataset with a max_length of 900.
Set Training Parameters and Fine-tune
With our data prepared and Llama initialized, we are ready to set our training parameters and commence training. With our H100 compute from Nebius, we are able toy leverage loading Llama-7B and our entire dataset of nearly 25,000 conversations into the GPU.
This snippet sets up the fine-tuning trainer for the model. It configures training with the tokenized dataset, specifying batch size, number of epochs, learning rate, and other hyperparameters. Mixed precision with bf16 is enabled to speed up training on compatible GPUs, and it uses an 8-bit Adam optimizer to reduce memory usage. Checkpoints are saved every epoch, and logging happens every 50 steps.
from trl import SFTConfig, SFTTrainer
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=tokenized_dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=12,
packing=True, # Speeds up training if sequences are often shorter than max length
args=SFTConfig(
per_device_train_batch_size=16, # Use large batch size with H100 80GB
gradient_accumulation_steps=1, # No accumulation needed if batch size fits
warmup_steps=500, # Warmup for a few hundred steps
num_train_epochs=3, # Train for 3 full epochs
learning_rate=3e-5, # More typical LR for full finetune
logging_steps=50, # Log every 50 steps
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=1337,
output_dir="outputs",
report_to="none", # No external reporting
bf16=True, # Enable bf16 mixed precision if supported
save_strategy="epoch", # Save checkpoints every epoch
eval_strategy="no", # Add evaluation if you have a val set
),
)
Once you have configured your trainer, call train(). With our H100, we were able to finish fine-tuning Llama-7B for 3 epochs in under two hours!
trainer_stats = trainer.train()
Once training has finished, save the model.
trainer.save_model("llama-3.1-8B-Instruct-medical-finetune")
tokenizer.save_pretrained("llama-3.1-8B-Instruct-medical-finetune")
If you would also like to look at your system resources that have been used during training, such as peak memory usage and max VRAM usage, use the snippet below.
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory / max_memory * 100, 3)
lora_percentage = round(used_memory_for_lora / max_memory * 100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.")
Prompting our Fine-Tuned model
Now that training has been completed, we can pass the same prompt as we did with Llama’s off-the-shelf weights. We will reuse the same StopOnTokens() function and alpaca_prompt for our setup.
from transformers import StoppingCriteria, StoppingCriteriaList
class StopOnTokens(StoppingCriteria):
def __init__(self, stop_strings, tokenizer):
self.stop_token_ids = [tokenizer.encode(s, add_special_tokens=False) for s in stop_strings]
def __call__(self, input_ids, scores, **kwargs):
for stop_id_seq in self.stop_token_ids:
if input_ids[0][-len(stop_id_seq):].tolist() == stop_id_seq:
return True
return False
stop_strings = ["### Instruction:"]
stopping_criteria = StoppingCriteriaList([StopOnTokens(stop_strings, tokenizer)])
alpaca_prompt = """You are a compassionate medical assistant. Provide clear and accurate medical advice based on the patient’s input and strong reasoning.
### Instruction:
{}
### Input:
{}
### Response:
"""
Now, passing the same prompt in, notice how our output is much more precise about its diagnosis and reasoning.
instruction = "What drug is most likely responsible for a 2-year-old child developing bone pain, vomiting, and features of increased intracranial pressure following excessive medication, with no presence of fever?"
input_context = ""
prompt_text = alpaca_prompt.format(instruction, input_context)
inputs = tokenizer([prompt_text], return_tensors="pt").to("cuda")
output = model.generate(
**inputs,
max_new_tokens=512,
stopping_criteria=stopping_criteria,
eos_token_id=tokenizer.eos_token_id,
streamer=text_streamer,
)
Output
<|begin_of_text|>You are a compassionate medical assistant. Provide clear and accurate medical advice based on the patient’s input and strong reasoning.
### Instruction:
What drug is most likely responsible for a 2-year-old child developing bone pain, vomiting, and features of increased intracranial pressure following excessive medication, with no presence of fever?
### Input:
### Response:
The symptoms of bone pain, vomiting, and increased intracranial pressure in a 2-year-old child, along with the absence of fever, strongly suggest a medication overdose. Given these symptoms, the drug most likely responsible is methotrexate, a chemotherapy medication. Methotrexate can cause bone pain due to its effect on bone marrow, and vomiting is a common side effect. Increased intracranial pressure could also result from methotrexate toxicity, which is known to cause central nervous system symptoms.
Let's consider other possibilities. Other drugs that might cause similar symptoms include nonsteroidal anti-inflammatory drugs (NSAIDs), which can lead to increased intracranial pressure, but they typically don't cause bone pain. Antibiotics like ceftriaxone can cause increased intracranial pressure, but they usually have a fever component, which is absent here.
The symptoms align closely with methotrexate toxicity, as it can cause a range of systemic issues, including bone pain and increased intracranial pressure, especially in young children. Therefore, methotrexate is the most likely culprit in this case. It would be prudent to investigate further to confirm this diagnosis and manage the child appropriately.
### Conclusion:
Based on the symptoms described—bone pain, vomiting, increased intracranial pressure, and the absence of fever—the drug most likely responsible is methotrexate. Methotrexate is a chemotherapy medication known to cause these systemic effects, particularly in children. It's important to investigate this further and manage the child's condition accordingly.<|eot_id|>
A Simpler MLOps Experience, Built for Productivity
With Nebius delivering immediate access to NVIDIA’s powerful H100 and H200 GPUs at nearly a fraction of cost of traditional cloud providers, Saturn Cloud users can achieve faster results, reduce expenses, and enjoy greater flexibility. Looking ahead, we’re excited to see how Saturn Cloud’s powerful platform continues to accelerate ML workflows across industries and use cases. Imagine the possibilities for your own projects: faster iteration cycles, increased accuracy, and quicker delivery of insights.
Whether you’re working on computer vision, NLP, or analytics at scale, Saturn Cloud is designed to help you achieve results faster.
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
