Fine Tuning OpenAI’s GPT3 Model

Photo credit: Jonathan Kemper on Unsplash
Introduction
OpenAI’s GPT-3 models have taken the world by storm with their impressive capabilities straight out of the box. However, it’s important to note that these models are primarily generalized and may require additional training to excel in specific use cases. While the base models perform well with well-crafted prompts and contextual examples, fine-tuning can eliminate the need for providing such examples and produce even better results.
The benefits are:
Fine-tuning GPT-3 models can improve the quality of results compared to the base model.
It can result in cost savings by reducing the length of prompts required.
Shorter prompts can lead to lower latency requests, making the model more efficient.
Fine-tuning allows the model to better understand the task without requiring large amounts of contextual data.
Overall, fine-tuning can enhance the performance of GPT-3 models for specific use cases, making them more accurate, efficient, and easier to train.
In this article, we’ll explore how OpenAI’s APIs can simplify the process of fine-tuning a model of your choice for specific use cases. With the help of these APIs, you can quickly and easily fine-tune a model and use it for inference right away, without requiring extensive coding knowledge or technical expertise. We’ll delve into the step-by-step process of fine-tuning and demonstrate how it can enhance the performance of GPT-3 models for niche tasks.
Setting up for the experiment
The only library that we need to install for fine-tuning and inference is the openai Python library which we can install via pip as follows -
pip install --upgrade openai
We also would need an OpenAI API Key which we can generate from their dashboard. The key is then assigned to an environment variable as follows -
export OPENAI_API_KEY="<OPENAI_API_KEY>"
Preparing the dataset
In this experiment, we are going to predict whether the headline of a news article is “Clickbait” or “Not Clickbait”. The dataset we are using can be found here and contains 32K rows half of which are labeled as “Clickbait”.

We have renamed the columns “headline” as “prompt” and “clickbait” as “completion” so as to meet the API requirements. The column “clickbait” was a boolean column in which 1 was replaced by “Clickbait” and 0 with “Not Clickbait”. The distribution of classes is as follows -
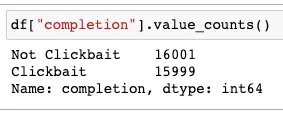
The API requires the data to be in JSONL format with two keys in each entry - “prompt” and “completion”. To convert the above Pandas dataframe into JSONL we run the following Python script -
df.to_json("./data/clickbait.jsonl", orient='records', lines=True)
This creates the clickbait.jsonl file with entires that look like
{
"prompt":"Should I Get Bings",
"completion":"Clickbait"
}
{
"prompt":"Which TV Female Friend Group Do You Belong In",
"completion":"Clickbait"
}
{
"prompt":"The New \"Star Wars: The Force Awakens\" Trailer Is Here To Give You Chills",
"completion":"Clickbait"
}
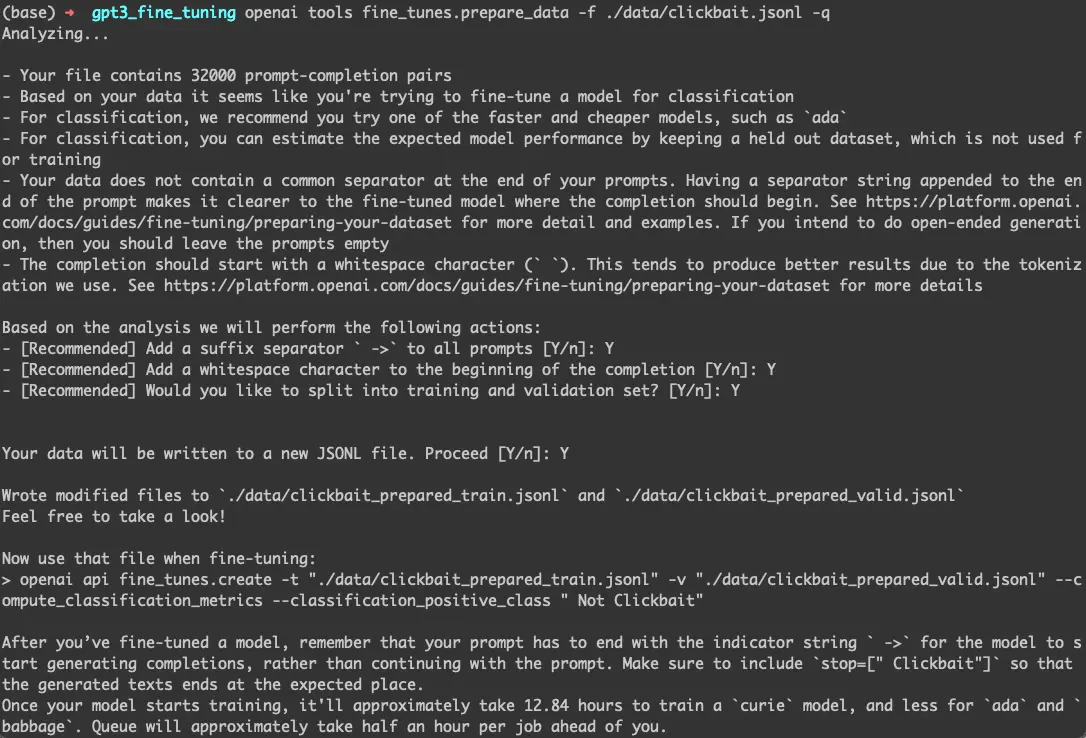
The training and validation sets are generated by running the following command -
openai tools fine_tunes.prepare_data -f ./data/clickbait.jsonl -q
Model Fine-Tuning
We are going to use the ada model for further fine-tuning. Is is because it is the fastest to train in comparison to the other models. A fine-tuning job is created by running the following command -
openai api fine_tunes.create -t "./data/clickbait_prepared_train.jsonl" -v "./data/clickbait_prepared_valid.jsonl" --compute_classification_metrics --classification_positive_class " Clickbait" -m ada
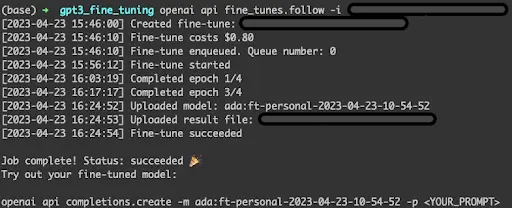
To check the status of the job, we can run -
openai api fine_tunes.follow -i <FINE-TUNING-ID>
Once the training is complete, we run the following command to get predictions -
openai api fine_tunes.results -i <FINE-TUNING-ID> > result.csv
Model Evaluation
The results.csv contains the following columns -
- step
- elapsed_tokens
- elapsed_examples
- training_loss
- training_sequence_accuracy
- training_token_accuracy
- validation_loss
- validation_sequence_accuracy
- validation_token_accuracy
- classification/accuracy
- classification/precision
- classification/recall
- classification/auroc
- classification/auprc
- classification/f1.0
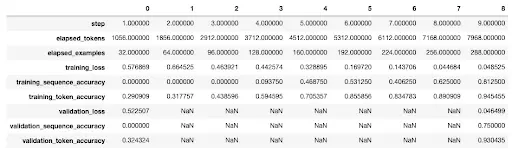
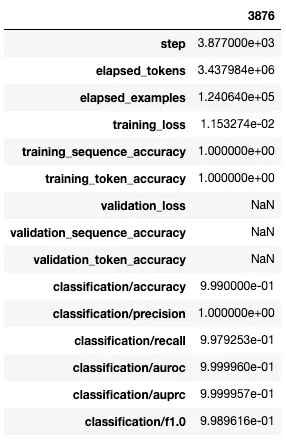
This is how the progress of fine-tuning looked like during the first 9 steps. The last entry in this CSV gives us the evaluation metrics for the fine-tuned model. As we can see that we have reached 100% precision and over 99.7% of recall. Nice!
Since the dataset is balanced, we could look at accuracy as a good evaluation metric. The accuracy of predictions on the dataset improved over time, as demonstrated by this figure -
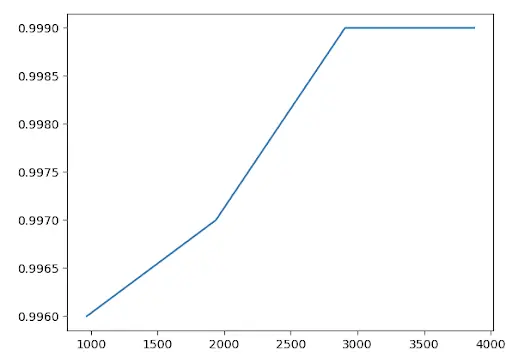
Model Accuracy during Traning
To check the various fine-tuned models and their metadata we can run the following command -
openai api fine_tunes.list
To run inference using our fine-tuned model we can directly call it via the Python API as demonstrated here -
ft_model = '<UPLOADED-MODEL-IDENTIFIER>'
res = openai.Completion.create(model=ft_model, prompt=prompt_text + '\n\n###\n\n', max_tokens=1, temperature=0)
res['choices'][0]['text']
Model Suite and Pricing
At the time of writing this article, OpenAI has priced fine-tuning their models as follows -
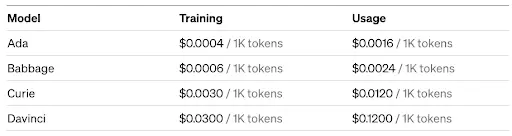
Fine Tuning Cost [Source: openai.com]
To calculate the number of tokens present in our text, we can use the tiktoken library.
Conclusion
I hope this short tutorial was helpful is understanding how to fine-tune OpenAI’s GPT3 models. The same process applies to all the other model offerings and the standardized template helps us to get started and run inference in no time.
References
You may also be interested in:
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
