Exporting Pandas DataFrame into a PDF file using Python

Table of Contents
- Why Export Pandas DataFrame to a PDF file?
- Exporting Pandas DataFrame to a PDF file using Python
- Conclusion
Why Export Pandas DataFrame to a PDF file?
Before diving into the technical details, let’s first understand why exporting a Pandas DataFrame into a PDF file can be useful. There are several reasons why you might want to do this:
Sharing data with non-technical stakeholders: If you need to share your data with people who are not familiar with programming or data science, a PDF file can be a great way to present your data in a readable and accessible format.
Archiving data for future reference: PDF files are a popular format for archiving documents and data. By exporting your DataFrame to a PDF file, you can ensure that your data is stored in a format that is easily accessible and can be viewed by anyone.
Creating reports: If you need to create reports based on your data, exporting your DataFrame to a PDF file can be a great way to present your findings in a professional and readable format.
Now that we have established why exporting a Pandas DataFrame into a PDF file can be useful, let’s move on to the technical details.
Exporting Pandas DataFrame to a PDF file using Python
There are several libraries in Python that can be used to export a Pandas DataFrame into a PDF file. In this article, we will focus on using the reportlab library to create a PDF file and the Pandas library to read in the data.
Installing the required libraries
Before we can start exporting our DataFrame to a PDF file, we need to install the required libraries. To install the reportlab library, simply run the following command in your terminal:
pip install reportlab
To install the Pandas library, run the following command:
pip install pandas
Creating a PDF file
To create a PDF file using the reportlab library, we first need to import the required modules:
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Table, TableStyle
from reportlab.lib import colors
Next, we create a SimpleDocTemplate object, which will be used to create our PDF file:
pdf = SimpleDocTemplate("dataframe.pdf", pagesize=letter)
In this example, we are creating a PDF file named dataframe.pdf. You can choose any name you like for your PDF file.
Reading in the data
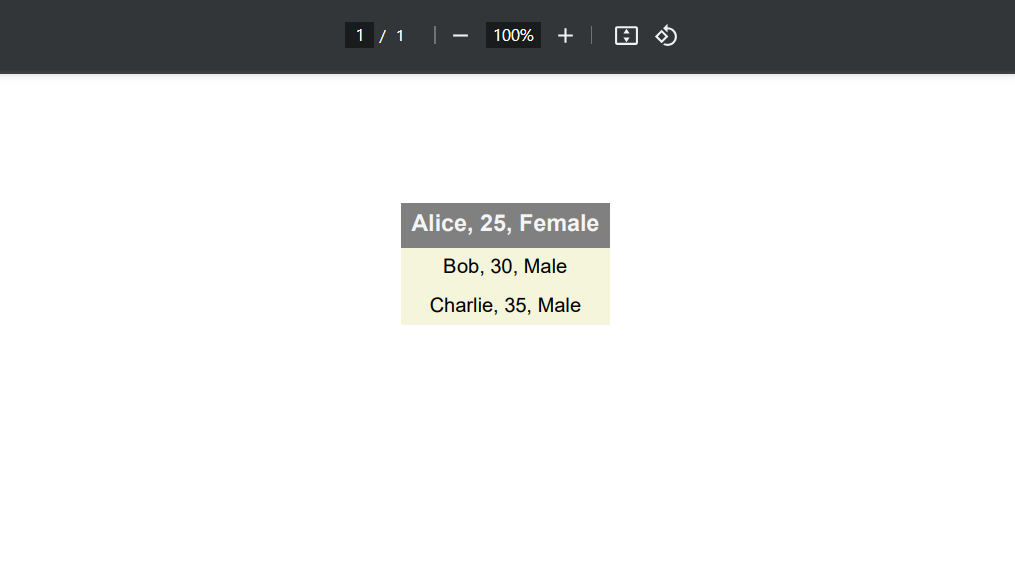
Now that we have created our PDF file object, we need to read in our data using the Pandas library. For this example, let’s assume that we have a CSV file named data.csv that contains the following data:
Alice, 25, Female
Bob, 30, Male
Charlie, 35, Male
To read this data into a dataframe, we use the following code:
import pandas as pd
data = pd.read_csv("data.csv")
Creating a table
Once we have read in our data, we can create a table using the Table module from the reportlab library:
table_data = []
for i, row in data.iterrows():
table_data.append(list(row))
table = Table(table_data)
In this example, we are iterating over each row in our DataFrame and appending it to a list. We then create a Table object using this list.
Adding style to the table
To make our table look more professional, we can add some style to it using the TableStyle module:
table_style = TableStyle([
('BACKGROUND', (0, 0), (-1, 0), colors.grey),
('TEXTCOLOR', (0, 0), (-1, 0), colors.whitesmoke),
('ALIGN', (0, 0), (-1, -1), 'CENTER'),
('FONTNAME', (0, 0), (-1, 0), 'Helvetica-Bold'),
('FONTSIZE', (0, 0), (-1, 0), 14),
('BOTTOMPADDING', (0, 0), (-1, 0), 12),
('BACKGROUND', (0, 1), (-1, -1), colors.beige),
('TEXTCOLOR', (0, 1), (-1, -1), colors.black),
('ALIGN', (0, 1), (-1, -1), 'CENTER'),
('FONTNAME', (0, 1), (-1, -1), 'Helvetica'),
('FONTSIZE', (0, 1), (-1, -1), 12),
('BOTTOMPADDING', (0, 1), (-1, -1), 8),
])
table.setStyle(table_style)
In this example, we are adding some basic styling to our table. We are setting the background color of the first row to grey, the text color to white, and the font to Helvetica-Bold. We are also setting the font size to 14 and adding some bottom padding.
Adding the table to the PDF file
Finally, we can add our table to the PDF file using the build method of our SimpleDocTemplate object:
pdf_table = []
pdf_table.append(table)
pdf.build(pdf_table)
In this example, we are creating a list of tables and adding our table to it. We then call the build method of our SimpleDocTemplate object and pass in our list of tables.
That’s it! We have now successfully exported our Pandas DataFrame to a PDF file using Python.
Conclusion
Exporting a Pandas DataFrame to a PDF file can be a great way to share your data with others in a readable and accessible format. In this article, we have discussed how to export a Pandas DataFrame to a PDF file using Python. We used the reportlab library to create a PDF file and the Pandas library to read in the data. We then created a table using the Table module and added some style to it using the TableStyle module. Finally, we added our table to the PDF file and saved it. With this knowledge, you can now export your own Pandas DataFrames to PDF files and share your data with others.
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
