Speeding up Neural Network Training With Multiple GPUs and Dask

The talk this blog post was based on.
A common moment when training a neural network is when you realize the model isn’t training quickly enough on a CPU and you need to switch to using a GPU. A less common, but still important, moment is when you realize that even a large GPU is too slow to train a model and you need further options.
One option is to connect multiple GPUs together across multiple machines so they can work as a unit and train a model more quickly. For most of the time, I’ve been using neural networks with the idea that connecting GPUs seemed outrageously difficult and maybe even only feasible for engineering teams trying to show off training large models. Thankfully, it turns out multi-GPU model training across multiple machines is pretty easy with Dask. This blog post is about my first experiment in using multiple GPUs with Dask and the results.
To see how to use Dask with GPUs to more quickly train a model, I first needed a model to try training. I decided to lean on my old friend, a neural network trained on Seattle pet license data, to generate realistic sounding pet names. I had previously used this neural network as an example in R, so switching it to Python and Dask seemed fun. I decided to use PyTorch for the framework, but still with a multi-layer LSTM to capture the patterns in the words.
 Some adorable names generated for adorable pets.
Some adorable names generated for adorable pets.
This whole blog post can be run for free on the Saturn Cloud Hosted free tier using the free Jupyter server and Dask clusters.
Model architecture
To train a neural network to generate realistic text, I needed the data to be properly formatted. Specifically, I want to predict each character in a name (as opposed to word in a sentence), so the base data was the beginning sequences of characters in text and the target data was next letter in the sequence of text. For example, to train a model on the pet name “SPOT” I would need to train it that a first letter is “S”, after “S” is “P,” after “SP”, is “O”, and so on. I used blanks used as filler and a special stop character indicate the name was complete. This was be made into a matrix as shown below (and if the data is too long I’d just truncate the earlier letters):
| X_1 | X_2 | X_3 | X_4 | X_5 | Y |
|---|---|---|---|---|---|
| (blank) | (blank) | (blank) | (blank) | (blank) | S |
| (blank) | (blank) | (blank) | (blank) | S | P |
| (blank) | (blank) | (blank) | S | P | O |
| (blank) | (blank) | S | P | O | T |
| (blank) | S | P | O | T | (stop) |
Each character was then 1-hot encoded (so given a dictionary value like A=1, B=2, etc and converted into vectors of 0s with one 1). With that, I got a 3-dimensional binary matrix as input to the model and 2-dimensional binary matrix as the target.
The network was four LSTM layers, plus a dense layer with a node for each character in the dictionary. The four LSTM layers would find the patterns within the text, and the dense mapped the results to each character-level prediction. For a single GPU, I would train the model using a single function:
def train():
device = torch.device(0) # Set GPU as the device
dataset = OurDataset(pet_names, device=device)
loader = DataLoader(dataset, batch_size=batch_size,
shuffle=True, num_workers=0)
model = Model()
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
dataset.permute()
for i, (batch_x, batch_y) in enumerate(loader):
optimizer.zero_grad()
batch_y_pred = model(batch_x)
loss = criterion(batch_y_pred.transpose(1, 2), batch_y)
loss.backward()
optimizer.step()
time = datetime.datetime.now().isoformat()
print(f"{time} - epoch {epoch} - loss {loss.item()}")
return model
(Full code for the final model can be found on this Saturn Cloud GitHub repo.)
Training with multiple GPUs
The basic idea to train with multiple GPUs is to use PyTorch’s Distributed Data Parallel (DDP) function. DDP will let multiple models being trained at the same time pass parameters between each other after each batch and compute the gradient concurrently. Thus, if you have three devices training a model with DDP, it’s equivalent to training a single model with a batch size that’s three times as large. Since the devices are all training concurrently, it’s theoretically possible that in this scenario, the model could be trained 3x faster than a model on a single device with a batch size 3x larger. In practice, this won’t be the case because of latency between the models when they communicate. But still, the results can be pretty good.
To turn my training code into a multi-GPU set up, I needed to make a few adjustments. First, I needed to add the PyTorch DDP wrapper around the model in the training future (and again the full code is available on GitHub):
model = Model()
model = model.to(device) # Was in single-GPU scenario
model = DDP(model) # Added for multi-GPU scenario
Next, any place in my training function where I might only want a single machine to do something (like write the output at the end of an Epoch),
I needed to wrap in a “only have one worker do this” logical statement. I used worker number 0 as the one to run these commands.
worker_rank = int(torch.distributed.get_rank())
if worker_rank == 0:
# ...
Then, I used dask.delayed to have multiple versions of the training function running concurrently. After adding a @dask.delayed decorator above the training function, I used dask_pytorch_ddp as a simpler wrapper around the functions to run them:
from dask_pytorch_ddp import dispatch
futures = dispatch.run(client, train)
Finally, to log the model results rather than having to coordinate where results are being saved within the Dask cluster, I used Weights and Biases as a place to store results and models.
Comparing results
For the analysis, I decided to try adjusting a number of parameters and see how a version with multiple-GPUs compared to a single GPU. Note that for simplicity in comparing, in the single GPU case I still used the DDP-based code but only with one machine (rather than removing that entirely)
- Networked GPUs - 1, 4, or 16
- Training batch size, per GPU - 1024, 4096, or 16384
- Model learning rate - 0.001, 0.004, or 0.016
Then, I used a Saturn Cloud Dask cluster to iterate though each of the combinations. Note that you have to be careful when comparing the results of the different experiments. For an equivalent comparison, if the number of networked GPUs went up by 4x you need to lower the training size per GPU to 1/4th the value. I, uh, may have spent hours trying to figure out what was wrong before I realized my comparisons weren’t equivalent. With that, here are the results:
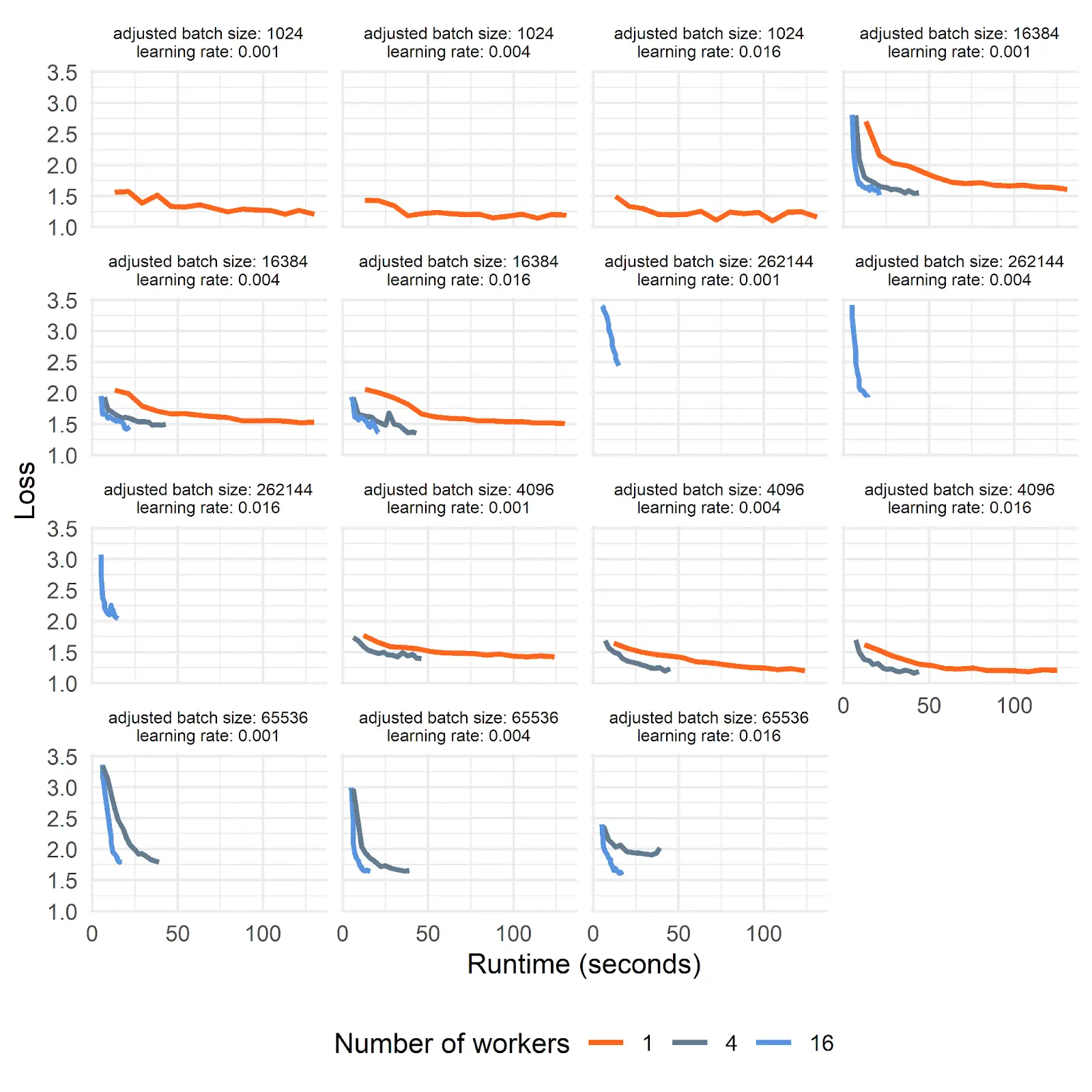
As you can see, using more GPUs can dramatically reduce the amount of time it takes to train the model, while still providing the same quality of model accuracy.
Here is a graph of the same data visualized in a different way–instead of showing the curves over the epochs of the training run, this is the amount of time it takes before the model hits a reasonable level of accuracy. You can see that increasing the number of GPUs by 4x can give you a nearly 4x increase in speed.
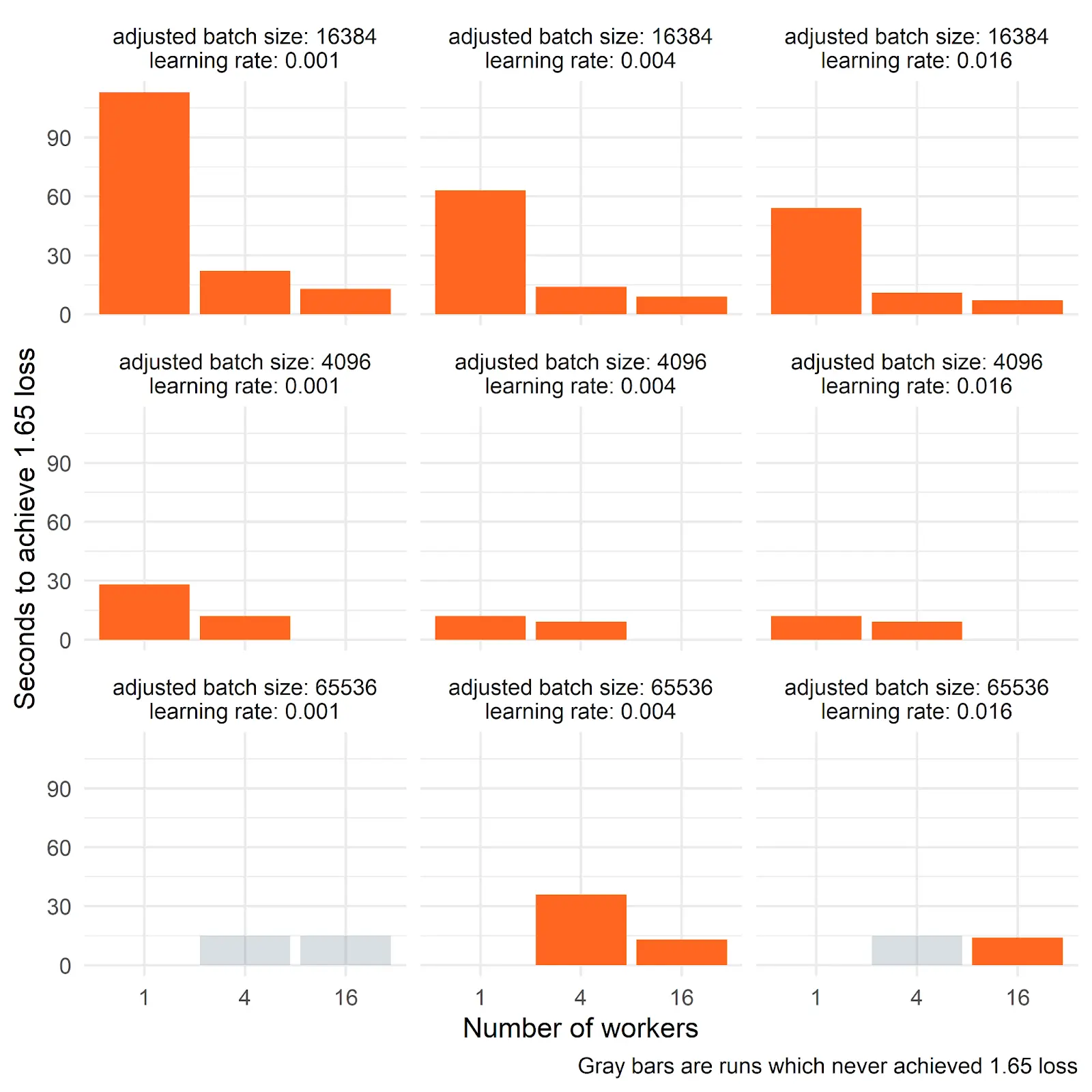
A few notes about these pretty amazing results. First, these techniques work best when your models need larger batch sizes because at that point. multiple GPUs aren’t just speeding up your results, but also you can avoid out of memory errors. So, if your problem is sufficiently simple, you might not get as much value out of using multiple GPUs, although there should still be a speed increase. Although, if the time it takes for your GPUs to communicate is high, then that can reduce the value of this too. Additionally, besides having multiple machines all coordinating GPU model training, one other option you have is to train with multiple GPUs on the same machine with resources like V100 graphics cards. That can be done using only DDP–having Dask communicate locally could still work, but would probably be redundant.
Besides using multiple GPUs with Dask to train the same model in a coordinated way, you could use Dask to concurrently train models with different sets of parameters. This allows you to explore a parameter space much faster–you could go faster still with tools like Dask-ML for fast hyper-parameter tuning.
Lastly, just to see the fruits of all this labor, below is a set of pet names the model generated (and you can generate them yourself here).
['Karfa', 'Samalpidells', 'Avexen', 'Ejynsp', 'Charlie', 'Kooie', 'Winnundie', 'Wunla', 'Scarlie A', 'Fli', 'Argio', 'Kucka', 'Karlor', 'Litr', 'Bheneng', 'Gelo', 'Cangalantynes', 'Mop', 'Nimi', 'Hary', 'Cassm Tur', 'Ullyne', 'Hollylof', 'Sopa', 'Ghugy', 'Bigde', 'Nucha', 'Mudser', 'Wridney', 'Mar Bas', 'Rugy Bi', 'Roba', 'Ruedel', 'Henrie', 'Sharlia Hu', 'Yellaj', 'Balil']
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
