Dask and pandas: There’s No Such Thing as Too Much Data

Do you love pandas, but hate when you reach the limits of your memory or compute resources? Dask gives you the chance to use the pandas API with distributed data and computing. In this article, you’ll learn how it really works, how to use it yourself, and why it’s worth the switch.
Introduction
Pandas is the beloved workhorse of the PyData toolkit — it makes incredibly diverse data analysis and data science tasks possible, using a user friendly and robust API. PyPi indicates that pandas is downloaded approximately 5 million times a week around the world.
However, pandas does struggle to meet the data scientist’s needs in a few cases where high volumes of data or unusually resource-intensive computation are required. In this article, we’ll discuss a few of the areas where users might find that Dask tools help expand the existing pandas functionality, without requiring changes of language or API.
Pandas Challenges
Before we proceed, let’s agree: pandas is awesome. This discussion is really about how we can add to the existing power of pandas, and is not about replacing all of pandas with super-high-powered Dask features. If pandas works for the use case in front of you and is the best way to get the job done, we recommend you use it!
But let’s take a look at the situations where you might need more.
Data is too large to hold in memory (memory constraint)
If you find yourself heavily downsampling data that might otherwise be useful, because it is too big for the single machine you’re using, then this is your problem. If you could run your job without loading the entire dataset into memory on a single machine, you could do your work with all the valuable data at your disposal. Dask has really ingenious infrastructure to make this work, which we’ll discuss in a moment.
Computation is too intensive/slow when run serially (compute constraint)
If you are running compute tasks for hours or even days or finding that pandas computation is so slow that you’re considering leaving the Python ecosystem entirely, then this is the problem you’re facing. Instead of tossing out Python, and adapting your code to a whole new language or framework like C++ or Java, you can apply some Dask principles with essentially the same API as pandas, and see exceptional acceleration of your job. We’ll explain how.
What’s Dask?
So what are we suggesting that you might find helpful when pandas can’t meet your needs? Dask!
Dask is an open-source framework that enables parallelization of Python code. This can be applied to all kinds of Python use cases, not just data science. Dask is designed to work well on single-machine setups and on multi-machine clusters. You can use Dask with not just pandas, but NumPy, scikit-learn, and other Python libraries. If you want to learn more about the other areas where Dask can be useful, there’s a great website explaining all of that.
When you use Dask, you change the way your computer handles your Python commands. Specifically, in the normal use of pandas, when you call a function, your Python interpreter computes the results immediately. The summary is created, or the calculations are conducted, or the filter is applied. This means that Python needs to have all the necessary data, and enough memory readily available to complete those computations. It also means that Python will do the steps one at a time, and if you have multiple functions to run, they’ll run in series. You’re limited, therefore, to the memory your machine has available, and the overall job will take as long as every step or calculation run one after the other.
If your data is pretty small, and the different computations are all quick to run, or vectorized, then this might be just fine! Then pandas is enough. However, if you’re working with very large or complicated data, or many groups within your data, you might find that you want to run multiple computations simultaneously.
Dask’s core advantage is a principle called “lazy evaluation” or “delayed” functions. Delaying a task with Dask can queue up a set of transformations or calculations so that it’s ready to run later, in parallel. This means that Python won’t evaluate the requested computations until explicitly told to. This differs from other kinds of functions, which compute instantly upon being called. Many very common and handy functions are ported to be native in Dask, which means they will be lazy (delayed computation) without you ever having to even ask.
You can go from that to something like this, where your tasks run in parallel when it is possible, vastly improving the speed and efficiency of your work
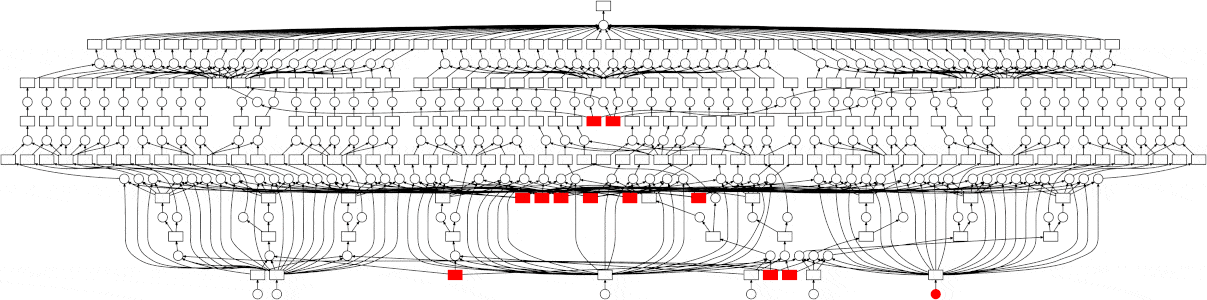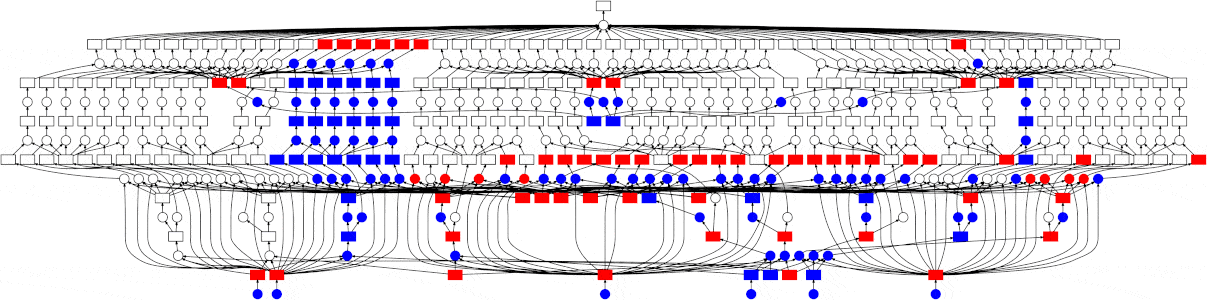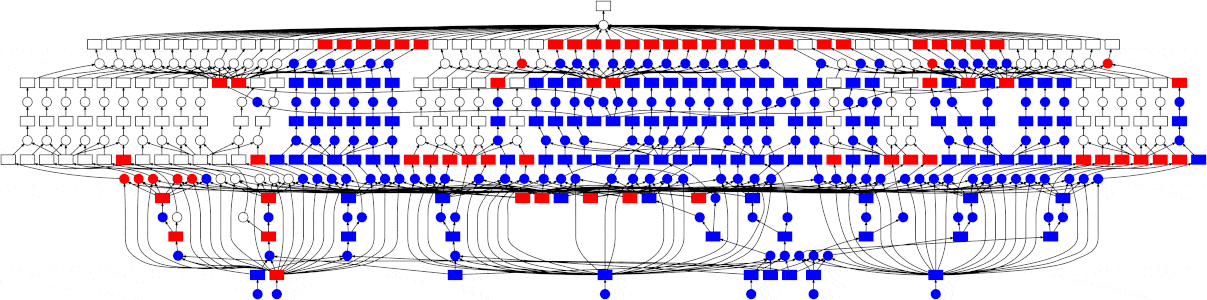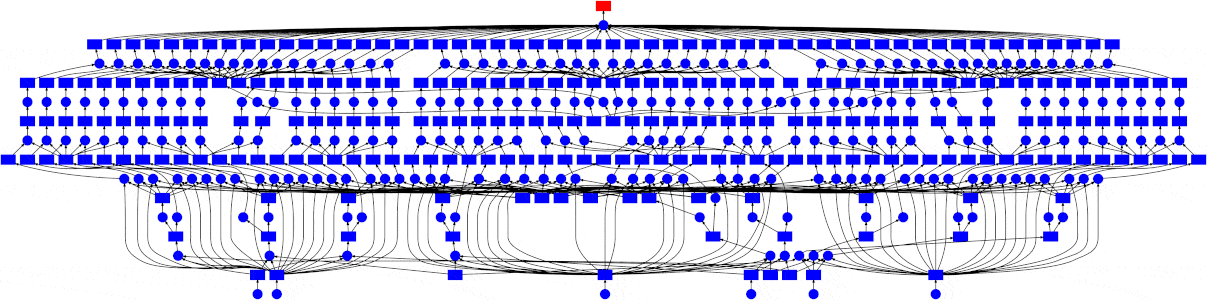
How It Works
You can incorporate Dask functionality in a number of different ways, all without making major changes or refactoring a whole lot of code.
Use Delayed Functions
You might like to use Dask native functions, or you might prefer to use @dask.delayed decoration on your custom functions: see our Data Scientist’s Guide to Lazy Evaluation to learn more!
Using these functions lets you create delayed objects that you can run later, in parallel, increasing the efficiency and speed of your job.
Delaying with Dask Dataframes
Another option is to switch from your pandas Dataframe objects to Dask Dataframes, which is what we’ll do here. This takes you from one discrete data object to a distributed data object, meaning your data can now be stored in partitions across the cluster of workers. Literally, your Dask Dataframe is a collection of smaller pandas Dataframes that are distributed across your cluster.

You might create a Dask Dataframe by:
- [Converting an existing pandas Dataframe:
dask.dataframe.from_pandas() - [Loading data directly into a Dask Dataframe: for example,
dask.dataframe.read_csv()
In addition to csv, Dask has built in capability to read lots of different types of data storage, including Parquet and JSON.
What’s the advantage of this, though?
A Dask Dataframe is distributed, so the computations you need to run on the Dataframe will be spread across the cluster, diffusing the workload. In addition, you never need to have a single machine that can hold the entire dataset, because the data itself is distributed for you. Plus, if you are loading your data from many different CSVs or other files, just tell Dask the folder path and it will load all those files into a single Dask Dataframe as partitions for you!
Example of loading a whole folder in one command into a Dask Dataframe:
import dask.dataframe as dd
files_2019 = 's3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv'
taxi = dd.read_csv(files_2019, storage_options={'anon': True}, assume_missing=True)
daskDF = taxi.persist()
_ = wait(daskDF)
#> CPU times: user 202 ms, sys: 39.4 ms, total: 241 ms
#> Wall time: 33.2 s
This is so fast in part because it’s lazily evaluated, like other Dask
functions. We’re using the .persist() method
to actually force the cluster to load our data from s3, because
otherwise it would just wait for our instruction to even start moving
data. After we say .persist(), it runs
parallel, so even loading the data is still quite fast.
In contrast, if we load the files in the folder as a regular pandas Dataframe, all the data has to be moved one file at a time, in order for us to have an object to work with:
import pandas as pd
import s3fs
s3 = s3fs.S3FileSystem(anon=True)
files_2019 = 's3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv'
all_files = s3.glob(files_2019)
df_from_each_file = (pd.read_csv(s3.open(f, mode='rb',),) for f in all_files)
pandasDF = pd.concat(df_from_each_file, ignore_index=True)
#> CPU times: user 2min 13s, sys: 40 s, total: 2min 53s
#> Wall time: 11min 15s
It works, but that’s some slow computation! And this is all working under the assumption that our machine can hold the data in memory, which is not always true.
What About…
Some pandas functions are faster than Dask at small data volumes — as the size of data grows, Dask’s advantage becomes evident. This is one of the reasons why sticking to pandas for small data may often be the right choice.
If you’re not sure whether your job needs Dask, assess how much time you’re spending on data loading, how slow the computations are, and whether you are having to cut corners (downsampling, or altering analyses) to get through the work. All of these are tell-tale signs that you are exceeding the capability of pandas and/or your single machine.
Now, let’s take a look at some very routine data manipulation tasks you might do in pandas, and see what they look like in Dask. We’re using large data, so here we should see Dask giving us a speed advantage.
Groupby
Here we’ll group the data by a column, then extract the mean of another
column. All that is different with Dask is that we run .compute() at the end so that computation is triggered and
results returned.
%%time
pandasDF.groupby("PULocationID").trip_distance.mean()
#> CPU times: user 938 ms, sys: 0 ns, total: 938 ms
#> Wall time: 937 ms
#> PULocationID
#> 1 1.586234
#> 2 8.915472
#> 3 7.342070
#> 4 2.695367
#> 5 24.207739
#> Name: trip_distance, Length: 263, dtype: float64
%%time
daskDF.groupby("PULocationID").trip_distance.mean().compute()
#> CPU times: user 36.1 ms, sys: 3.52 ms, total: 39.6 ms
#> Wall time: 390 ms
#> PULocationID
#> 1.0 1.586234
#> 2.0 8.915472
#> 3.0 7.342070
#> 4.0 2.695367
#> 5.0 24.207739
#> Name: trip_distance, Length: 263, dtype: float64
Analyze a Column
What if we don’t group, but just calculate a single metric of a column?
Same situation, our code snippets are identical with the addition of
.compute().
%%time
pandasDF[["trip_distance"]].mean()
#> CPU times: user 515 ms, sys: 86 ms, total: 601 ms
#> Wall time: 600 ms
#> trip_distance 3.000928
#> dtype: float64
%%time
daskDF[["trip_distance"]].mean().compute()
#> CPU times: user 43.4 ms, sys: 0 ns, total: 43.4 ms
#> Wall time: 342 ms
#> trip_distance 3.000928
#> dtype: float64
Drop Duplicates
Here’s one that we need a lot, and which requires looking across all the data – dropping duplicates. Dask has this too!
%%time
pandasDF.drop_duplicates("passenger_count")
#> CPU times: user 1.5 s, sys: 232 ms, total: 1.73 s
#> Wall time: 1.73 s
%%time
daskDF.drop_duplicates("passenger_count").compute()
#> *CPU times: user 24.1 ms, sys: 2.22 ms, total: 26.4 ms
#> Wall time: 362 ms
Performance Comparisons
So, where do these examples leave us? We are using the same data, and almost identical code, but we just added a Dask cluster to increase the power.
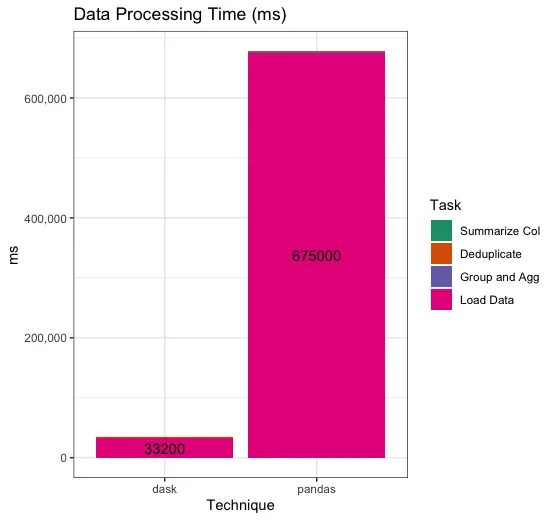
First, we can take a look at a plot of the runtime of our steps — but because pandas takes over 11 minutes to load the data, it overwhelms everything else! Our data processing is barely visible as a tiny dark bar at the top of the processing runtime.
So, we can omit the loading time, which we can easily see is vastly worse in pandas, and then we see the individual processing tasks we tried.
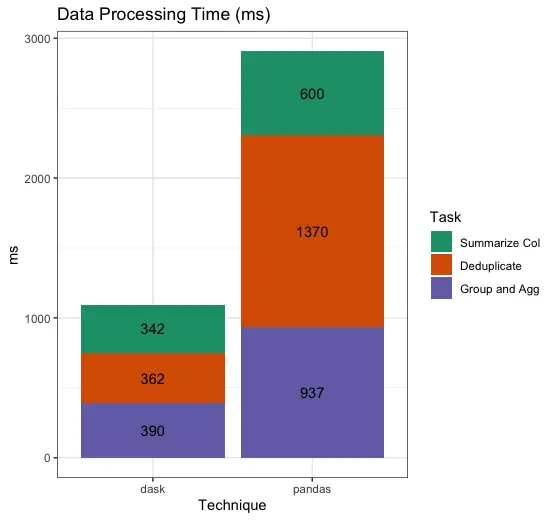
Overall, by using Dask we saved 11 minutes in load time, as well as reducing our overall data processing time by more than half.
Total runtime, pandas: 677,907 ms Total runtime, dask: 34,294 ms
Pandas takes 20x longer than dask to run this overall task pipeline.
Cost
But then again, you might think, “pandas is free, right?” Sure, on your laptop pandas is free (although I’d argue that your time is valuable!) But running this on dask isn’t as costly as you might think. Also, we ran our test case here on an EC2 machine, so pandas wasn’t free in this example either.
All machines are r5.2xlarge instances. At time of writing, these are priced by AWS EC2 at $0.504 per hour, each. These contain 8 VCPU cores each, and 64 GB of memory.
Dask cluster: (1 client + 4 cluster workers) 5 r5.2xlarge x $0.504/hr = $2.52/hr * 34,294 ms (aka 0.0095 hr) = $0.02394
pandas: 1 r5.2xlarge x $0.504/hr = $0.504/hr * 677,907 ms (aka 0.1883 hr) = $0.0949
So, for this task, Dask cost us about 2 cents while pandas cost us more than 9 cents.
If we add on the premium that Saturn Cloud charges to the Dask side, to be scrupulously fair, then the arithmetic looks like this.
Saturn Dask cluster: (1 client + 4 cluster workers) 5 r5.2xlarge x $1.14/hr = $5.70/hr * 34,294 ms (aka 0.0095 hr) = $0.05415
pandas: 1 r5.2xlarge x $0.504/hr = $0.504/hr * 677,907 ms (aka 0.1883 hr) = $0.0949
Dask still only costs 5 cents, to the 9 we’re paying for pandas. 20x faster, and half the price- not bad!
Conclusion I hope that this article has helped demystify some of the aspects of switching to Dask from pandas, and will give you encouragement to try these new, exciting technologies for your own data science! Dask clusters are cheaper than you think, run spectacularly fast, and are really easy to use if you already know pandas and other PyData libraries. If you’d like to try this for free, sign up for Saturn Cloud Hosted.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
