Breaking the Data Barrier: How Zero-Shot, One-Shot, and Few-Shot Learning are Transforming Machine Learning

Photo credit: Allison Saeng via Unsplash
Introduction
In today’s fast-changing world, technology is improving every day and Machine Learning and Artificial Intelligence have revolutionized a variety of industries with the power of process automation and improved efficiency. However, humans still have a distinct advantage over traditional machine learning algorithms because these algorithms require thousands of samples to respond to the underlying correlations and identify an object.
Imagine the frustration of unlocking your smartphone using fingerprints or facial recognition by performing 100 scans just before the algorithm works. This type of function would never have been put on the market.
However, since 2005, machine learning experts have developed new algorithms that could completely change the game. The improvements made over the last almost two decades have produced algorithms that can learn from the smallest (Zero, One or Few) number of samples.
In this article, we explore the concepts behind those algorithms and provide a comprehensive understanding of how these learning techniques function, while also shedding light on some challenges faced when implementing them.
How does Zero-Shot Learning work?
Zero-shot learning is the concept of training a model to classify objects it has never seen before. The core idea is to exploit the existing knowledge of another model to obtain meaningful representations of new classes.
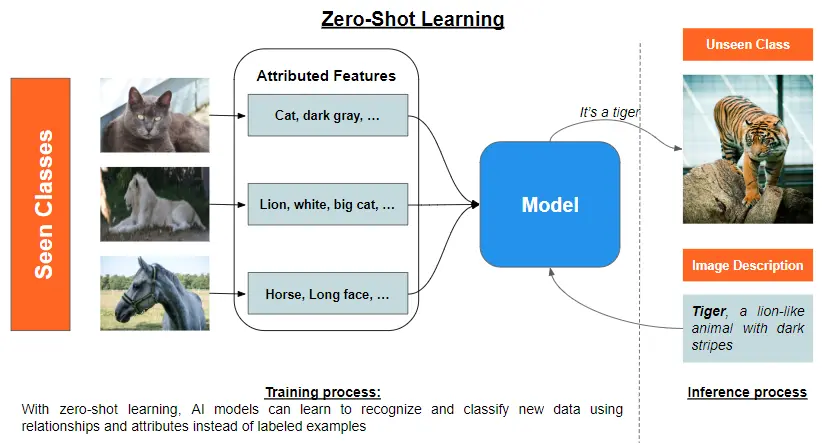
It uses semantic embeddings or attribute-based learning to leverage prior knowledge in a meaningful way that can provide a high-level understanding of relationships between known and unknown classes. Both can be used together or independently.
Semantic Embeddings are vector representations of words, phrases, or documents that capture the underlying meaning and relationship between them in a continuous vector space. These embeddings are typically generated using unsupervised learning algorithms, such as Word2Vec, GloVe, or BERT. The goal is to create a compact representation of the linguistic information, where similar meanings are encoded with similar vectors. In this way, semantic embeddings allow for efficient and accurate comparisons and manipulation of textual data and to generalize to unseen classes by projecting instances into a continuous, shared semantic space.
Attribute-Based Learning enables the classification of objects from unseen classes without access to any labeled examples of those classes. It decomposes objects into their meaningful and noticeable properties, which serve as an intermediate representation, allowing the model to establish a correspondence between seen and unseen classes. This process typically involves attribute extraction, attribute prediction, and label inference.
Attribute extraction involves deriving meaningful and discriminative attributes for each object class to bridge the gap between low-level features and high-level concepts.
Attribute prediction involves learning a correspondence between low-level features of instances and high-level attributes, using ML techniques to recognize patterns and relationships between features to generalize to novel classes.
Label inference involves predicting a new instance’s class label using its predicted attributes and the relationships between attributes and unseen class labels, without relying on labeled examples.
Despite the promising potential of zero-shot learning, several challenges remain, such as:
- Domain Adaptation: The distribution of instances in the target domain may differ significantly from that in the source domain, leading to a discrepancy between the semantic embeddings learned for seen and unseen classes. This domain shift can harm the performance, as the model may not establish a meaningful correspondence between instances and attributes across domains. To overcome this challenge, various domain adaptation techniques have been proposed, such as adversarial learning, feature disentangling, and self-supervised learning, by aiming to align the distributions of instances and attributes in the source and target domains.
How does One-shot Learning work?
In the process of developing a traditional neural network, for example to identify cars, the model needs thousands of samples, captured from different angles and with different contrasts, in order to effectively differentiate them. One-shot learning takes a different approach. Instead of identifying the car in question, the method determines whether image A is equivalent to image B. This is obtained by generalizing the information the model has gained from experience with previous tasks. One-shot learning is mainly used in computer vision.
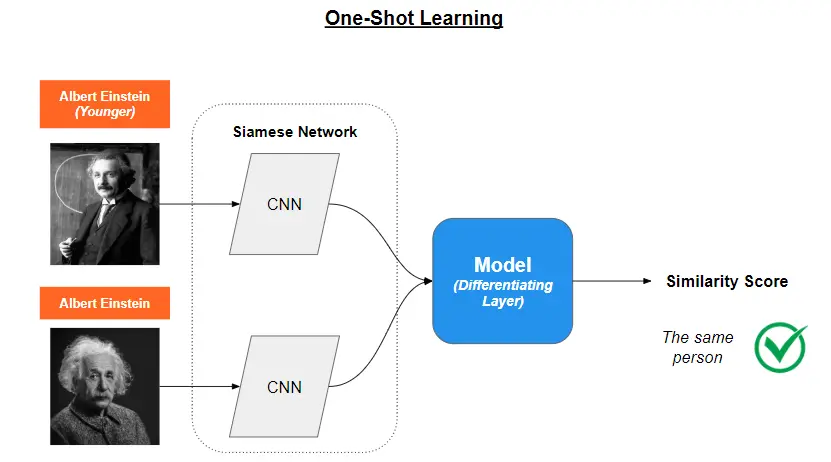
Techniques used to achieve this include Memory Augmented Neural Networks (MANNs) and Siamese Networks. By leveraging these techniques independently, one-shot learning models can quickly adapt to new tasks and perform well even with very limited data, making them suitable for real-world scenarios where obtaining labeled data can be expensive or time-consuming.
Memory Augmented Neural Networks (MANNs) are a class of advanced neural networks designed to learn from very few examples, similar to how humans can learn from just one instance of a new object. MANNs achieve this by having an extra memory component that can store and access information over time.
Imagine a MANN as a smart robot with a notebook. The robot can use its notebook to remember things it has seen before and use that information to understand new things it encounters. This helps the robot to learn much faster than a regular AI model.
Siamese Networks, on the other side, are designed to compare data samples by employing two or more identical subnetworks with shared weights. These networks learn a feature representation that captures essential differences and similarities between data samples.
Imagine Siamese Networks as a pair of twin detectives who always work together. They share the same knowledge and skills, and their job is to compare two items and decide if they’re the same or different. These detectives look at the important features of each item and then compare their findings to decide.
The training of a Siamese network evolves two stages: The Verification and the Generalization stage.
During the verification, the network determines whether the two input images or data points belong to the same class or not. The network processes both inputs separately using twin subnetworks.
During the generalization, the model generalizes its understanding of the input data by effectively learning the feature representation that can discriminate between different classes.
Once the two stages have been carried out, the model is capable of determining whether image A corresponds to image B.
One-shot learning is very promising because it does not need to be retrained to detect new classes. However, it faces challenges, such as high memory requirements and immense need for computational power, since twice as many operations are needed for learning.
How does Few-Shot Learning work?
The last learning method to be presented is Few-Shot Learning, a subfield of meta-learning, aiming to develop algorithms capable of learning from a few labeled examples.
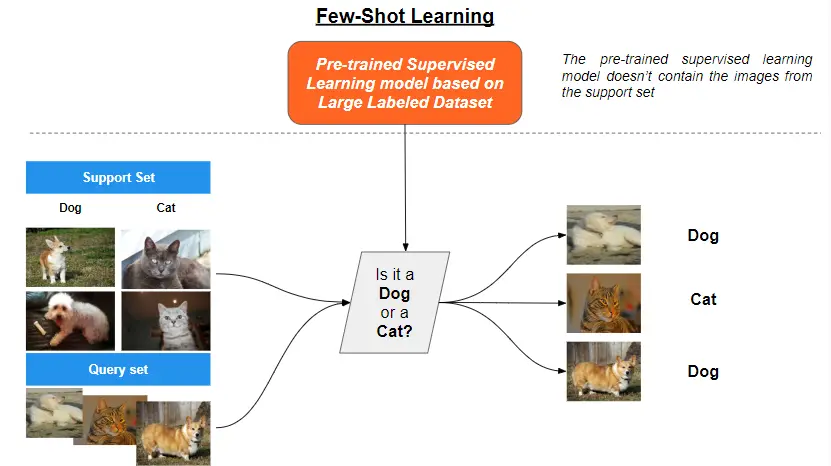
In this context, Prototypical Networks and Model-Agnostic Meta-Learning (MAML) are two prominent alternative techniques that have demonstrated success in few-shot learning scenarios.
Prototypical Networks
Prototypical Networks are a class of neural networks designed for few-shot classification tasks. The core idea is to learn a prototype, or a representative example, for each class in the feature space. The prototypes serve as a basis for classification by comparing the distance between a new input and the learned prototypes.
Three main steps are involved:
Embedding: The network computes an embedding for each input using a neural network encoder, such as a Convolutional Neural Network (CNN) or a Recurrent Neural Network (RNN). The embeddings are high-dimensional representations that capture the salient features of the input data.
Prototype computation: For each class, the network computes the prototype by taking the mean of the embeddings of the support set, which is a small subset of labeled examples for each class. The prototype represents the “center” of the class in the feature space.
Classification: Given a new input, the network calculates its embedding and computes the distance (e.g. Euclidean distance) between the input’s embedding and the prototypes. The input is then assigned to the class with the nearest prototype.
The learning process involves minimizing a loss function that encourages the prototypes to be closer to the embeddings of their respective class and farther away from the embeddings of other classes.
Model-Agnostic Meta-Learning (MAML)
MAML is a meta-learning algorithm that aims to find an optimal initialization for the model’s parameters, such that it can rapidly adapt to new tasks with a few gradient steps. MAML is model-agnostic, meaning it can be applied to any model that is trained with gradient descent.
MAML involves the following steps:
Task sampling: During meta-training, tasks are sampled from a distribution of tasks, where each task is a few-shot learning problem with a few labeled examples.
Task-specific learning: For each task, the model’s parameters are fine-tuned using the task’s training data (support set) with a few gradient steps. This results in task-specific models with updated parameters.
Meta-learning: The meta-objective is to minimize the sum of the task-specific losses on the validation data (query set) for all tasks. The model’s initial parameters are updated via gradient descent to achieve this objective.
Meta-testing: After meta-training, the model can be quickly fine-tuned on new tasks with a few gradient steps, leveraging the learned initialization.
MAML requires significant computational resources, as it involves multiple nested gradient updates which raise challenges. One such challenge is Task Diversity. In many few-shot learning scenarios, the model must adapt to a wide range of tasks or classes, each with only a few examples. This diversity can make it challenging to develop a single model or approach that can effectively handle different tasks or classes without extensive fine-tuning or adaptation.
Conclusion
The incredible world of machine learning has gifted us with groundbreaking techniques like Zero-Shot, One-Shot, and Few-Shot Learning. These approaches allow AI models to learn and recognize objects or patterns with only a handful of examples, much like the way humans do. This opens up a world of possibilities across various industries, such as healthcare, retail, and manufacturing, where access to vast amounts of labeled data isn’t always a luxury.
SHARE:



About Saturn Cloud
Saturn Cloud is a portable AI platform that installs securely in any cloud account. Build, deploy, scale and collaborate on AI/ML workloads-no long term contracts, no vendor lock-in.
Saturn Cloud provides customizable, ready-to-use cloud environments
for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without having to switch tools.
